Build a 100% Serverless REST API with Firebase Functions & FaunaDB
Publikováno: 31.10.2019
Indie and enterprise web developers alike are pushing toward a serverless architecture for modern applications. Serverless architectures typically scale well, avoid the need for server provisioning and most importantly are easy and cheap to set up! And that’s why I believe the next evolution for cloud is serverless because it enables developers to focus on writing applications.
With that in mind, let’s build a REST API (because will we ever stop making these?) using 100% serverless technology.
We’re going to … Read article
The post Build a 100% Serverless REST API with Firebase Functions & FaunaDB appeared first on CSS-Tricks.
Indie and enterprise web developers alike are pushing toward a serverless architecture for modern applications. Serverless architectures typically scale well, avoid the need for server provisioning and most importantly are easy and cheap to set up! And that’s why I believe the next evolution for cloud is serverless because it enables developers to focus on writing applications.
With that in mind, let’s build a REST API (because will we ever stop making these?) using 100% serverless technology.
We’re going to do that with Firebase Cloud Functions and FaunaDB, a globally distributed serverless database with native GraphQL.
Those familiar with Firebase know that Google’s serverless app-building tools also provide multiple data storage options: Firebase Realtime Database and Cloud Firestore. Both are valid alternatives to FaunaDB and are effectively serverless.
But why choose FaunaDB when Firestore offers a similar promise and is available with Google’s toolkit? Since our application is quite simple, it does not matter that much. The main difference is that once my application grows and I add multiple collections, then FaunaDB still offers consistency over multiple collections whereas Firestore does not. In this case, I made my choice based on a few other nifty benefits of FaunaDB, which you will discover as you read along — and FaunaDB’s generous free tier doesn’t hurt, either. 😉
In this post, we’ll cover:
- Installing Firebase CLI tools
- Creating a Firebase project with Hosting and Cloud Function capabilities
- Routing URLs to Cloud Functions
- Building three REST API calls with Express
- Establishing a FaunaDB Collection to track your (my) favorite video games
- Creating FaunaDB Documents, accessing them with FaunaDB’s JavaScript client API, and performing basic and intermediate-level queries
- And more, of course!
Set Up A Local Firebase Functions Project
For this step, you’ll need Node v8 or higher. Install firebase-tools globally on your machine:
$ npm i -g firebase-toolsThen log into Firebase with this command:
$ firebase loginMake a new directory for your project, e.g. mkdir serverless-rest-api and navigate inside.
Create a Firebase project in your new directory by executing firebase login.
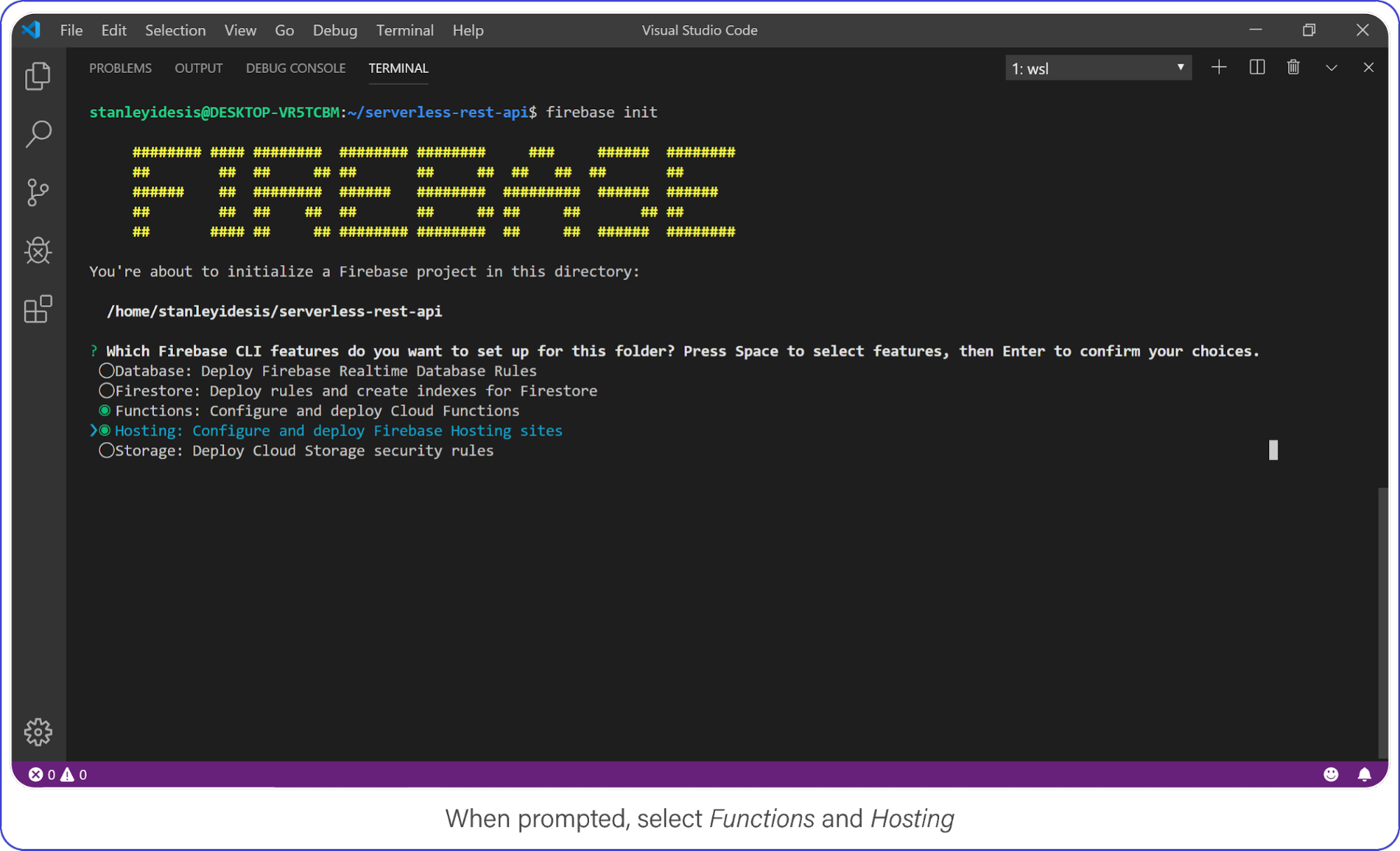
Choose "functions" and "hosting" when the bubbles appear, create a brand new firebase project, select JavaScript as your language, and choose yes (y) for the remaining options.
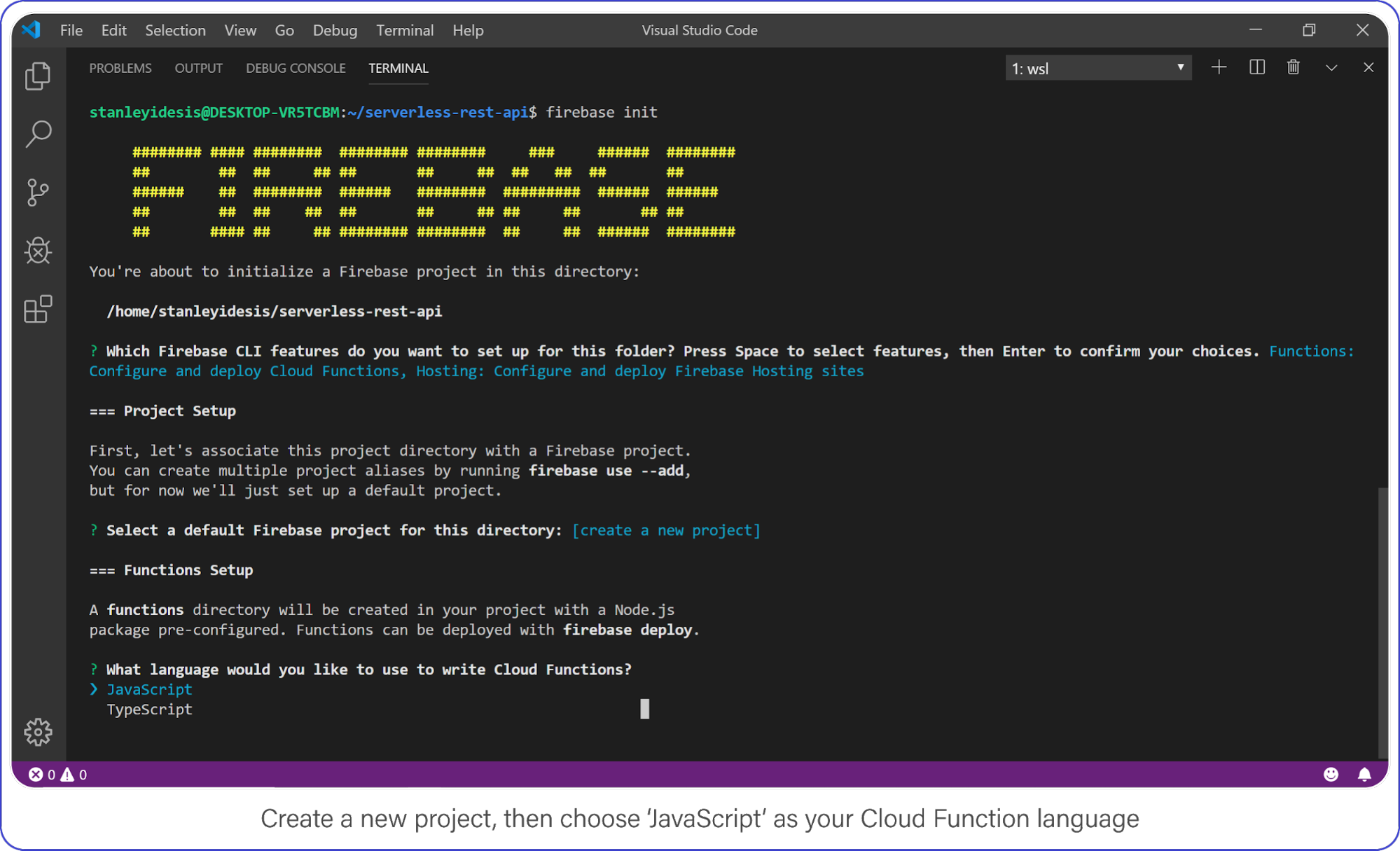
Once complete, enter the functions directory, this is where your code lives and where you’ll add a few NPM packages.
Your API requires Express, CORS, and FaunaDB. Install it all with the following:
$ npm i cors express faunadbSet Up FaunaDB with NodeJS and Firebase Cloud Functions
Before you can use FaunaDB, you need to sign up for an account.
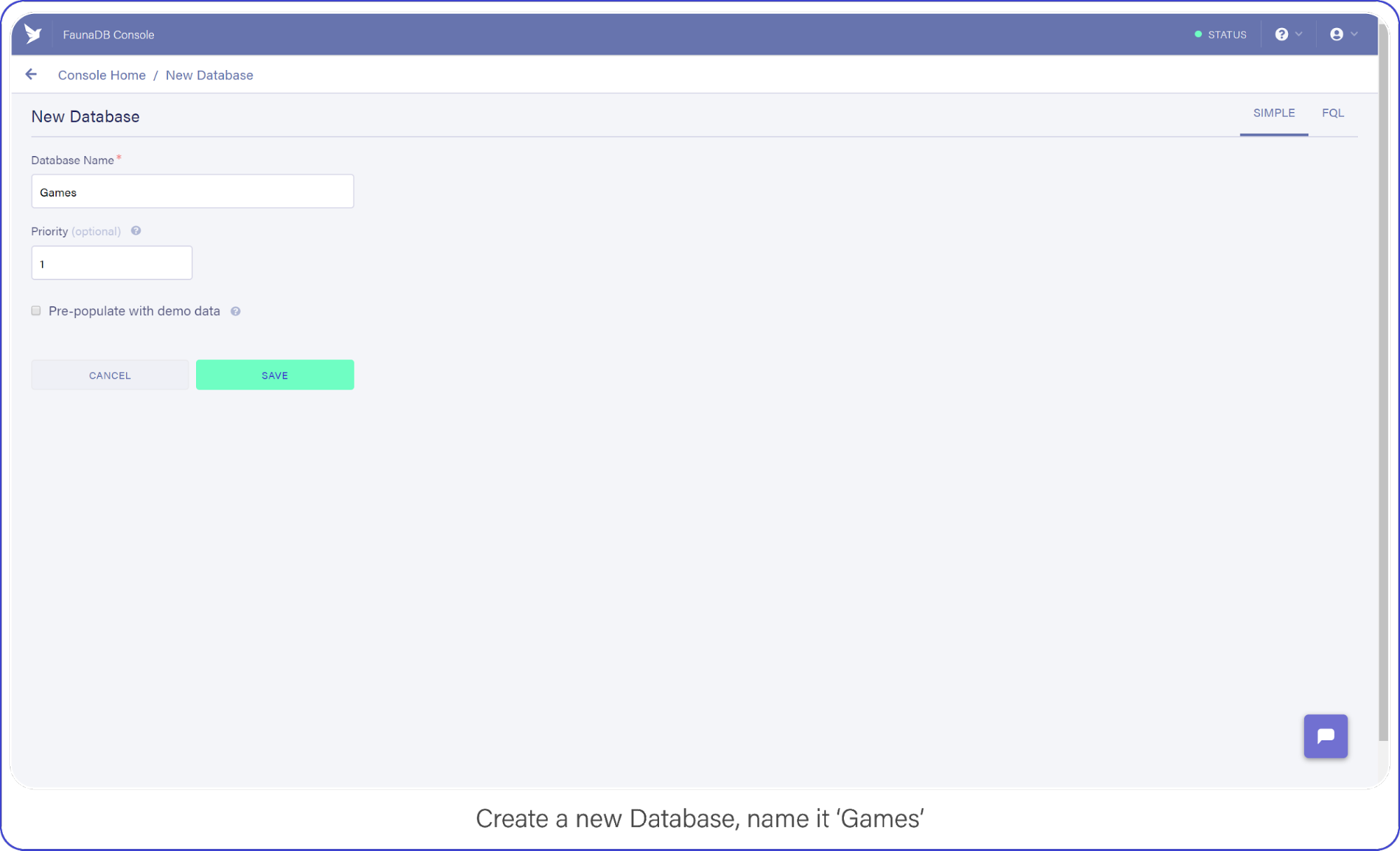
When you’re signed in, go to your FaunaDB console and create your first database, name it "Games."
You’ll notice that you can create databases inside other databases . So you could make a database for development, one for production or even make one small database per unit test suite. For now we only need ‘Games’ though, so let’s continue.
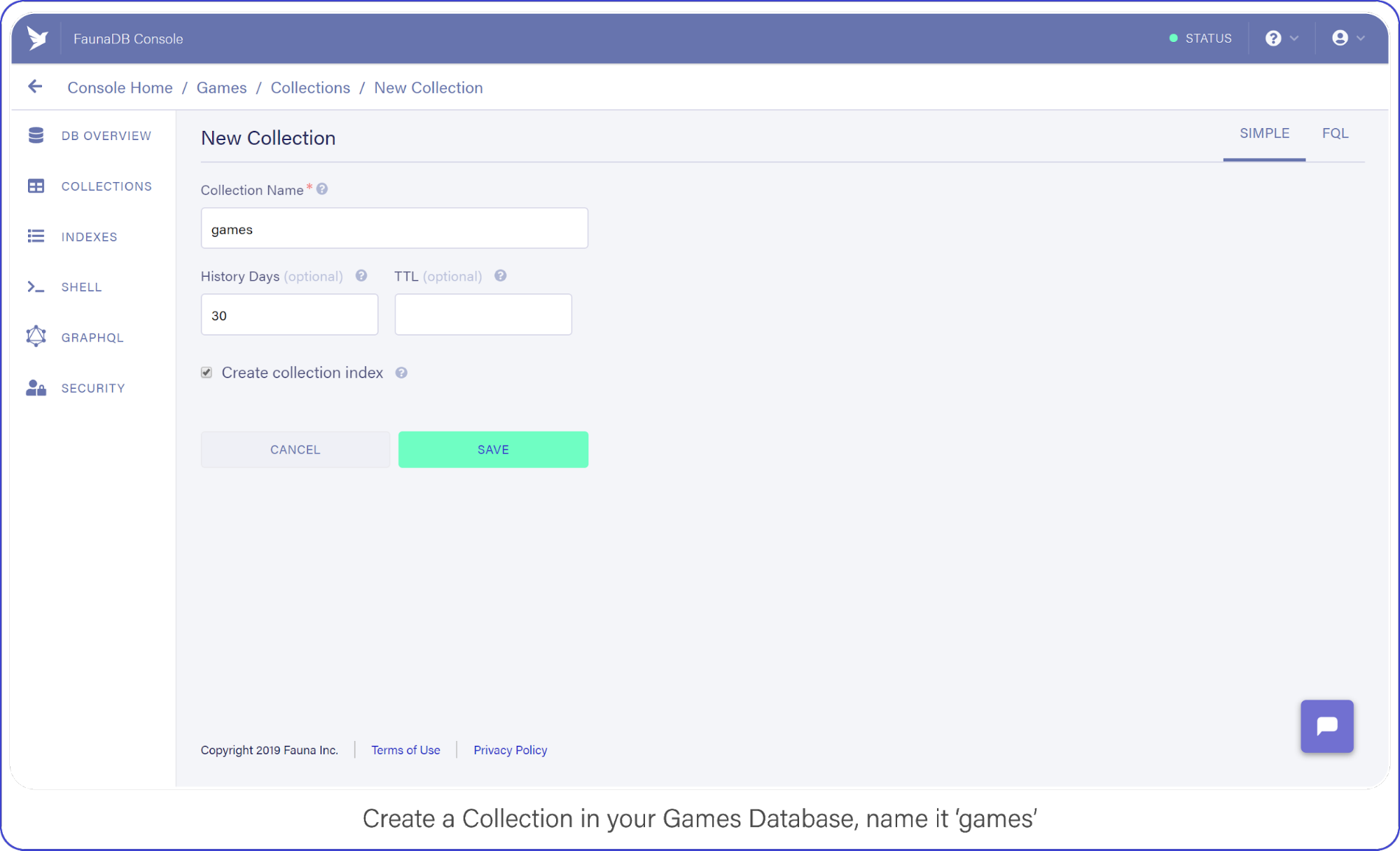
Then tab over to Collections and create your first Collection named ‘games’. Collections will contain your documents (games in this case) and are the equivalent of a table in other databases— don’t worry about payment details, Fauna has a generous free-tier, the reads and writes you perform in this tutorial will definitely not go over that free-tier. At all times you can monitor your usage in the FaunaDB console.
For the purpose of this API, make sure to name your collection ‘games’ because we’re going to be tracking your (my) favorite video games with this nerdy little API.
Tab over to Security, and create a new Key and name it "Personal Key." There are 3 different types of keys, Admin/Server/Client. Admin key is meant to manage multiple databases, A Server key is typically what you use in a backend which allows you to manage one database. Finally a client key is meant for untrusted clients such as your browser. Since we’ll be using this key to access one FaunaDB database in a serverless backend environment, choose ‘Server key’.
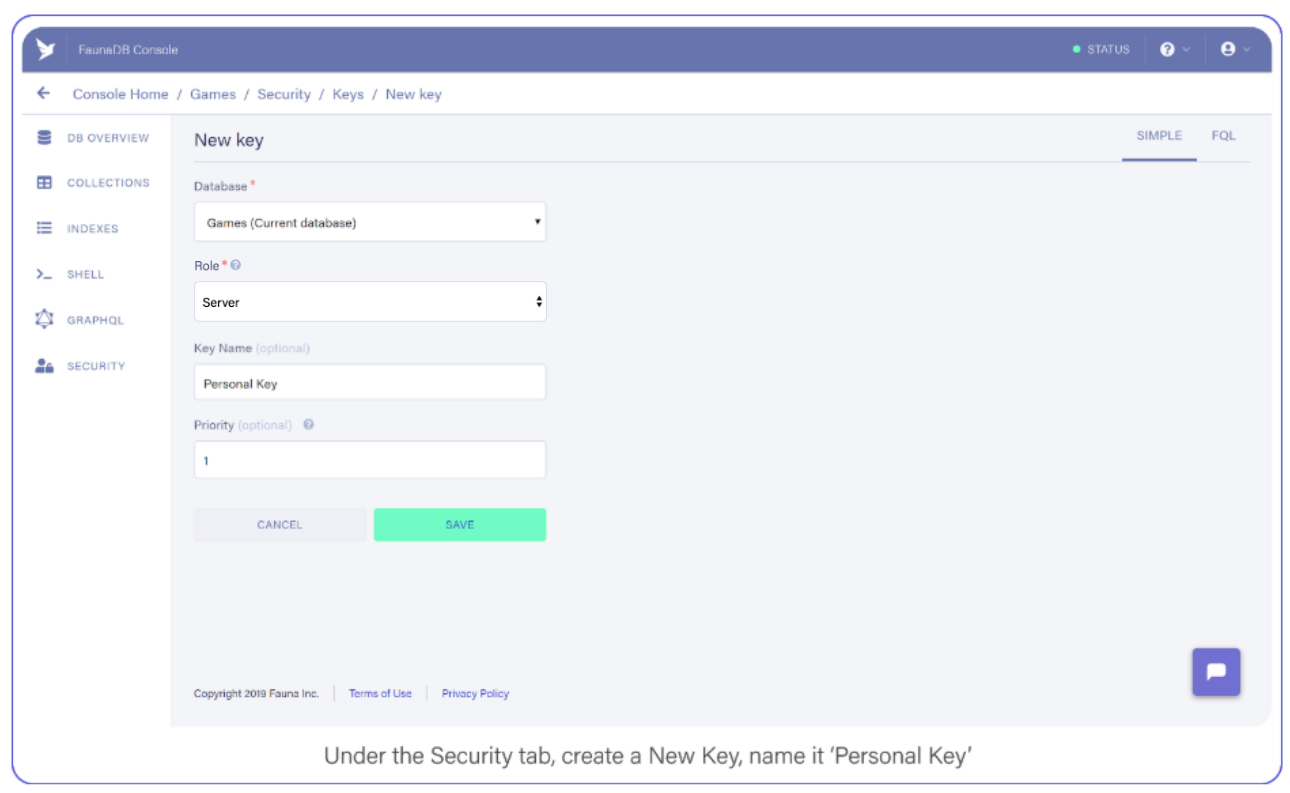
Save the key somewhere, you’ll need it shortly.
Build an Express REST API with Firebase Functions
Firebase Functions can respond directly to external HTTPS requests, and the functions pass standard Node Request and Response objects to your code — sweet. This makes Google’s Cloud Function requests accessible to middleware such as Express.
Open index.js inside your functions directory, clear out the pre-filled code, and add the following to enable Firebase Functions:
const functions = require('firebase-functions')
const admin = require('firebase-admin')
admin.initializeApp(functions.config().firebase)Import the FaunaDB library and set it up with the secret you generated in the previous step:
admin.initializeApp(...)
const faunadb = require('faunadb')
const q = faunadb.query
const client = new faunadb.Client({
secret: 'secrety-secret...that’s secret :)'
})Then create a basic Express app and enable CORS to support cross-origin requests:
const client = new faunadb.Client({...})
const express = require('express')
const cors = require('cors')
const api = express()
// Automatically allow cross-origin requests
api.use(cors({ origin: true }))You’re ready to create your first Firebase Cloud Function, and it’s as simple as adding this export:
api.use(cors({...}))
exports.api = functions.https.onRequest(api)This creates a cloud function named, “api” and passes all requests directly to your api express server.
Routing an API URL to a Firebase HTTPS Cloud Function
If you deployed right now, your function’s public URL would be something like this: https://project-name.firebaseapp.com/api. That’s a clunky name for an access point if I do say so myself (and I did because I wrote this... who came up with this useless phrase?)
To remedy this predicament, you will use Firebase’s Hosting options to re-route URL globs to your new function.
Open firebase.json and add the following section immediately below the "ignore" array:
"ignore": [...],
"rewrites": [
{
"source": "/api/v1**/**",
"function": "api"
}
]This setting assigns all /api/v1/... requests to your brand new function, making it reachable from a domain that humans won’t mind typing into their text editors.
With that, you’re ready to test your API. Your API that does... nothing!
Respond to API Requests with Express and Firebase Functions
Before you run your function locally, let’s give your API something to do.
Add this simple route to your index.js file right above your export statement:
api.get(['/api/v1', '/api/v1/'], (req, res) => {
res
.status(200)
.send(`<img src="https://media.giphy.com/media/hhkflHMiOKqI/source.gif">`)
})
exports.api = ...Save your index.js fil, open up your command line, and change into the functions directory.
If you installed Firebase globally, you can run your project by entering the following: firebase serve.
This command runs both the hosting and function environments from your machine.
If Firebase is installed locally in your project directory instead, open package.json and remove the --only functions parameter from your serve command, then run npm run serve from your command line.
Visit localhost:5000/api/v1/ in your browser. If everything was set up just right, you will be greeted by a gif from one of my favorite movies.
And if it’s not one of your favorite movies too, I won’t take it personally but I will say there are other tutorials you could be reading, Bethany.
Now you can leave the hosting and functions emulator running. They will automatically update as you edit your index.js file. Neat, huh?
FaunaDB Indexing
To query data in your games collection, FaunaDB requires an Index.
Indexes generally optimize query performance across all kinds of databases, but in FaunaDB, they are mandatory and you must create them ahead of time.
As a developer just starting out with FaunaDB, this requirement felt like a digital roadblock.
"Why can’t I just query data?" I grimaced as the right side of my mouth tried to meet my eyebrow.
I had to read the documentation and become familiar with how Indexes and the Fauna Query Language (FQL) actually work; whereas Cloud Firestore creates Indexes automatically and gives me stupid-simple ways to access my data. What gives?
Typical databases just let you do what you want and if you do not stop and think: : "is this performant?" or “how much reads will this cost me?” you might have a problem in the long run. Fauna prevents this by requiring an index whenever you query.
As I created complex queries with FQL, I began to appreciate the level of understanding I had when I executed them. Whereas Firestore just gives you free candy and hopes you never ask where it came from as it abstracts away all concerns (such as performance, and more importantly: costs).
Basically, FaunaDB has the flexibility of a NoSQL database coupled with the performance attenuation one expects from a relational SQL database.
We’ll see more examples of how and why in a moment.
Adding Documents to a FaunaDB Collection
Open your FaunaDB dashboard and navigate to your games collection.
In here, click NEW DOCUMENT and add the following BioShock titles to your collection:
{ "title": "BioShock", "consoles": [ "windows", "xbox_360", "playstation_3", "os_x", "ios", "playstation_4", "xbox_one" ], "release_date": Date("2007-08-21"), "metacritic_score": 96 } { "title": "BioShock 2", "consoles": [ "windows", "playstation_3", "xbox_360", "os_x" ], "release_date": Date("2010-02-09"), "metacritic_score": 88 }{ "title": "BioShock Infinite", "consoles": [ "windows", "playstation_3", "xbox_360", "os_x", "linux" ], "release_date": Date("2013-03-26"), "metacritic_score": 94 }
As with other NoSQL databases, the documents are JSON-style text blocks with the exception of a few Fauna-specific objects (such as Date used in the "release_date" field).
Now switch to the Shell area and clear your query. Paste the following:
Map(Paginate(Match(Index("all_games"))),Lambda("ref",Var("ref")))And click the "Run Query" button. You should see a list of three items: references to the documents you created a moment ago.
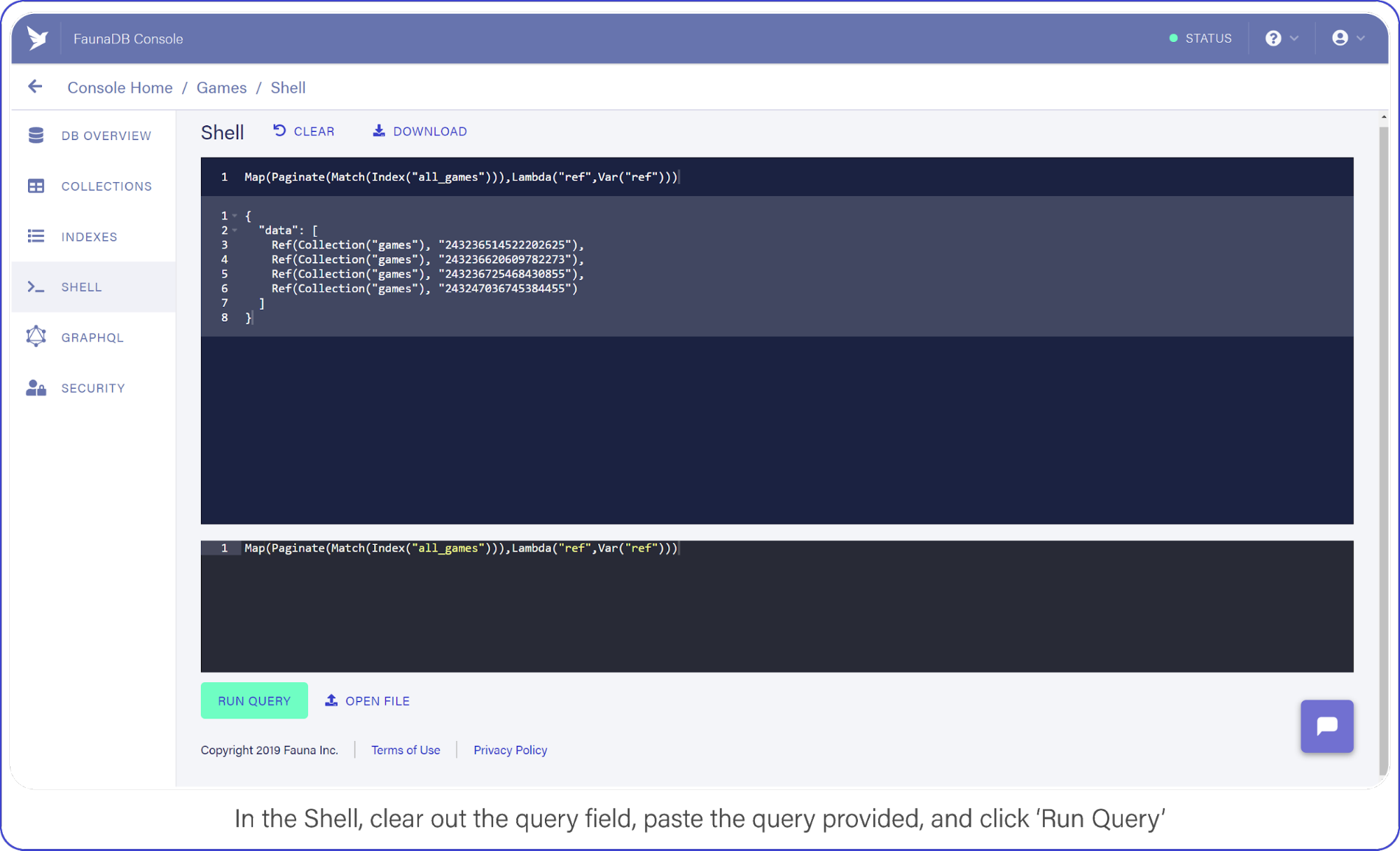
It’s a little long in the tooth, but here’s what the query is doing.
Index("all_games") creates a reference to the all_games index which Fauna generated automatically for you when you established your collection.These default indexes are organized by reference and return references as values. So in this case we use the Match function on the index to return a Set of references. Since we do not filter anywhere, we will receive every document in the ‘games’ collection.
The set that was returned from Match is then passed to Paginate. This function as you would expect adds pagination functionality (forward, backward, skip ahead). Lastly, you pass the result of Paginate to Map, which much like its software counterpart lets you perform an operation on each element in a Set and return an array, in this case it is simply returning ref (the reference id).
As we mentioned before, the default index only returns references. The Lambda operation that we fed to Map, pulls this ref field from each entry in the paginated set. The result is an array of references.
Now that you have a list of references, you can retrieve the data behind the reference by using another function: Get.
Wrap Var("ref") with a Get call and re-run your query, which should look like this:
Map(Paginate(Match(Index("all_games"))),Lambda("ref",Get(Var("ref"))))Instead of a reference array, you now see the contents of each video game document.
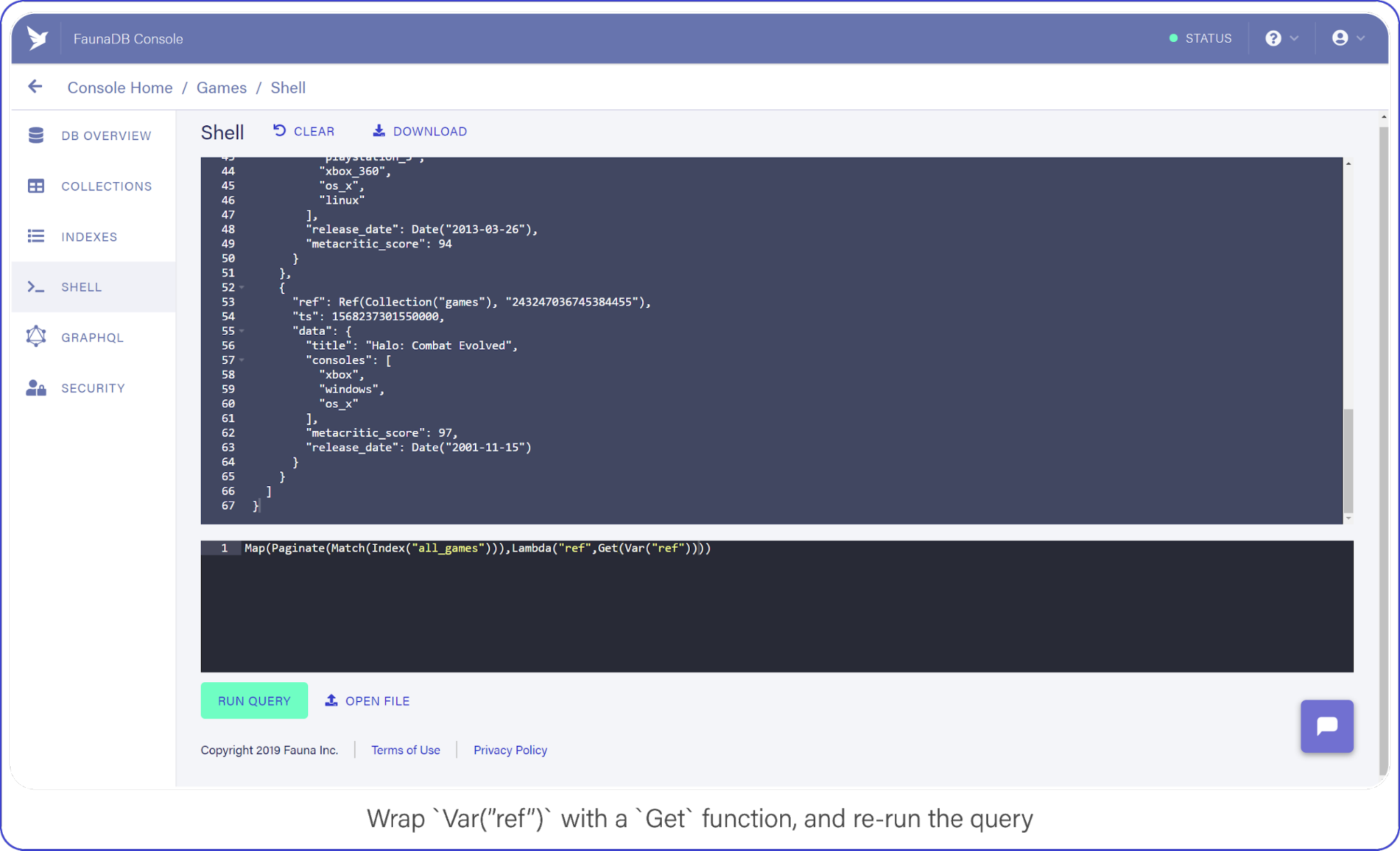
Var("ref") with a Get function, and re-run the query.Now that you have an idea of what your game documents look like, you can start creating REST calls, beginning with a POST.
Create a Serverless POST API Request
Your first API call is straightforward and shows off how Express combined with Cloud Functions allow you to serve all routes through one method.
Add this below the previous (and impeccable) API call:
api.get(['/api/v1', '/api/v1/'], (req, res) => {...})
api.post(['/api/v1/games', '/api/v1/games/'], (req, res) => {
let addGame = client.query(
q.Create(q.Collection('games'), {
data: {
title: req.body.title,
consoles: req.body.consoles,
metacritic_score: req.body.metacritic_score,
release_date: q.Date(req.body.release_date)
}
})
)
addGame
.then(response => {
res.status(200).send(`Saved! ${response.ref}`)
return
})
.catch(reason => {
res.error(reason)
})
})Please look past the lack of input sanitization for the sake of this example (all employees must sanitize inputs before leaving the work-room).
But as you can see, creating new documents in FaunaDB is easy-peasy.
The q object acts as a query builder interface that maps one-to-one with FQL functions (find the full list of FQL functions here).
You perform a Create, pass in your collection, and include data fields that come straight from the body of the request.
client.query returns a Promise, the success-state of which provides a reference to the newly-created document.
And to make sure it’s working, you return the reference to the caller. Let’s see it in action.
Test Firebase Functions Locally with Postman and cURL
Use Postman or cURL to make the following request against localhost:5000/api/v1/ to add Halo: Combat Evolved to your list of games (or whichever Halo is your favorite but absolutely not 4, 5, Reach, Wars, Wars 2, Spartan...)
$ curl http://localhost:5000/api/v1/games -X POST -H "Content-Type: application/json" -d '{"title":"Halo: Combat Evolved","consoles":["xbox","windows","os_x"],"metacritic_score":97,"release_date":"2001-11-15"}'If everything went right, you should see a reference coming back with your request and a new document show up in your FaunaDB console.
Now that you have some data in your games collection, let’s learn how to retrieve it.
Retrieve FaunaDB Records Using a REST API Request
Earlier, I mentioned that every FaunaDB query requires an Index and that Fauna prevents you from doing inefficient queries. Since our next query will return games filtered by a game console, we can’t simply use a traditional `where` clause since that might be inefficient without an index. In Fauna, we first need to define an index that allows us to filter.
To filter, we need to specify which terms we want to filter on. And by terms, I mean the fields of document you expect to search on.
Navigate to Indexes in your FaunaDB Console and create a new one.
Name it games_by_console, set data.consoles as the only term since we will filter on the consoles. Then set data.title and ref as values. Values are indexed by range, but they are also just the values that will be returned by the query. Indexes are in that sense a bit like views, you can create an index that returns a different combination of fields and each index can have different security.
To minimize request overhead, we’ve limited the response data (e.g. values) to titles and the reference.
Your screen should resemble this one:
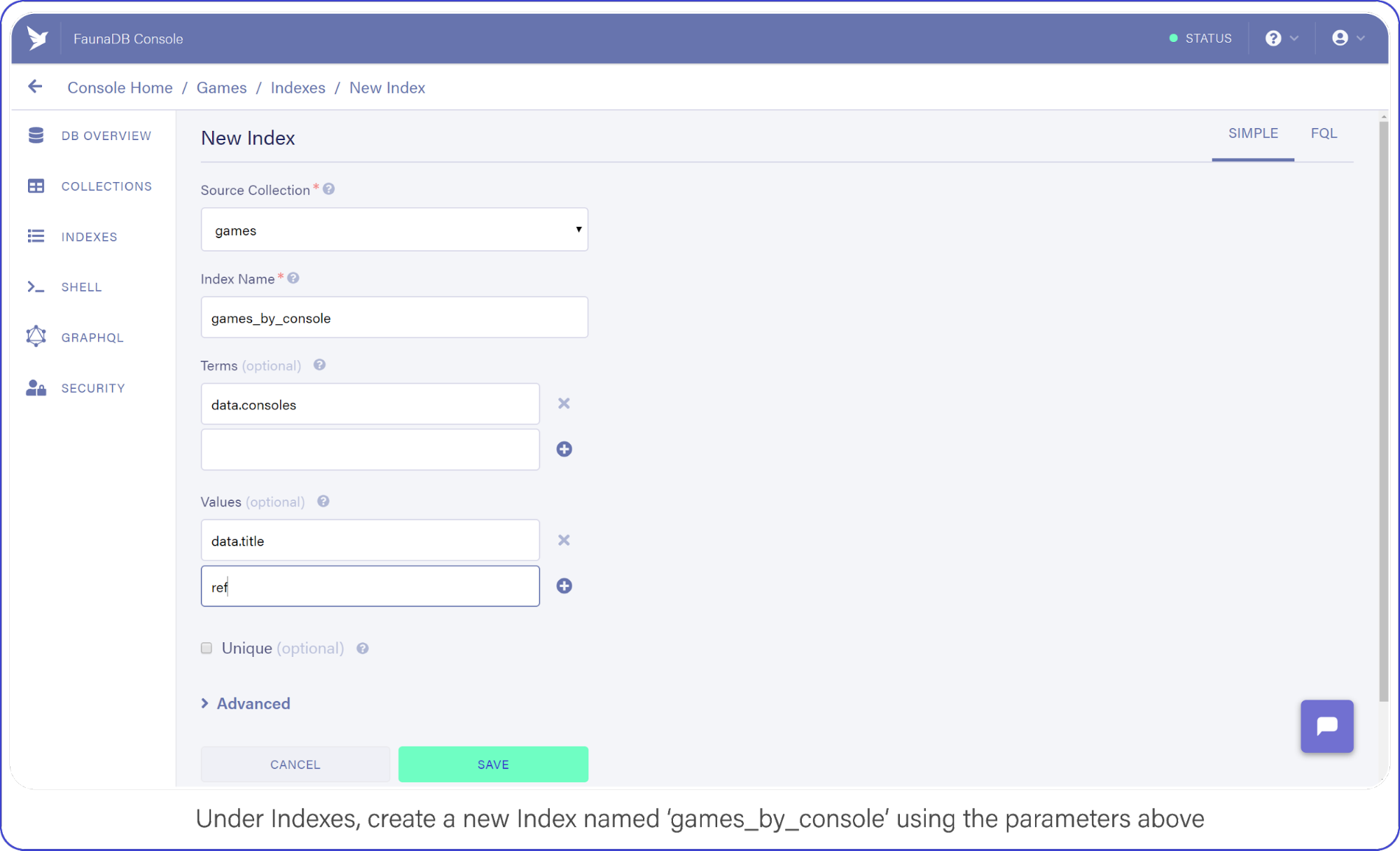
games_by_console using the parameters above.Click "Save" when you’re ready.
With your Index prepared, you can draft up your next API call.
I chose to represent consoles as a directory path where the console identifier is the sole parameter, e.g. /api/v1/console/playstation_3, not necessarily best practice, but not the worst either — come on now.
Add this API request to your index.js file:
api.post(['/api/v1/games', '/api/v1/games/'], (req, res) => {...})
api.get(['/api/v1/console/:name', '/api/v1/console/:name/'], (req, res) => {
let findGamesForConsole = client.query(
q.Map(
q.Paginate(q.Match(q.Index('games_by_console'), req.params.name.toLowerCase())),
q.Lambda(['title', 'ref'], q.Var('title'))
)
)
findGamesForConsole
.then(result => {
console.log(result)
res.status(200).send(result)
return
})
.catch(error => {
res.error(error)
})
})This query looks similar to the one you used in your SHELL to retrieve all games, but with a slight modification.This query looks similar to the one you used in your SHELL to retrieve all games, but with a slight modification. Note how your Match function now has a second parameter (req.params.name.toLowerCase()) which is the console identifier that was passed in through the URL.
The Index you made a moment ago, games_by_console, had one Term in it (the consoles array), this corresponds to the parameter we have provided to the match parameter. Basically, the Match function searches for the string you pass as its second argument in the index. The next interesting bit is the Lambda function. Your first encounter with Lamba featured a single string as Lambda’s first argument, “ref.”
However, the games_by_console Index returns two fields per result, the two values you specified earlier when you created the Index (data.title and ref). So basically we receive a paginated set containing tuples of titles and references, but we only need titles. In case your set contains multiple values, the parameter of your lambda will be an array. The array parameter above (`['title', 'ref']`) says that the first value is bound to the text variable title and the second is bound to the variable ref. text parameter. These variables can then be retrieved again further in the query by using Var(‘title’). In this case, both “title” and “ref,” were returned by the index and your Map with Lambda function maps over this list of results and simply returns only the list of titles for each game.
In fauna, the composition of queries happens before they are executed. When you write var q = q.Match(q.Index('games_by_console'))), the variable just contains a query but no query was executed yet. Only when you pass the query to client.query(q) to be executed, it will execute. You can even pass javascript variables in other Fauna FQL functions to start composing queries. his is a big benefit of querying in Fauna vs the chained asynchronous queries required of Firestore. If you ever have tried to generate very complex queries in SQL dynamically, then you will also appreciate the composition and less declarative nature of FQL.
Save index.js and test out your API with this:
$ curl http://localhost:5000/api/v1/xbox
{"data":["Halo: Combat Evolved"]}Neat, huh? But Match only returns documents whose fields are exact matches, which doesn’t help the user looking for a game whose title they can barely recall.
Although Fauna does not offer fuzzy searching via indexes (yet), we can provide similar functionality by making an index on all words in the string. Or if we want really flexible fuzzy searching we can use the filter syntax. Note that its is not necessarily a good idea from a performance or cost point of view… but hey, we’ll do it because we can and because it is a great example of how flexible FQL is!
Filtering FaunaDB Documents by Search String
The last API call we are going to construct will let users find titles by name. Head back into your FaunaDB Console, select INDEXES and click NEW INDEX. Name the new Index, games_by_title and leave the Terms empty, you won’t be needing them.
Rather than rely on Match to compare the title to the search string, you will iterate over every game in your collection to find titles that contain the search query.
Remember how we mentioned that indexes are a bit like views. In order to filter on title , we need to include `data.title` as a value returned by the Index. Since we are using Filter on the results of Match, we have to make sure that Match returns the title so we can work with it.
Add data.title and ref as Values, compare your screen to mine:
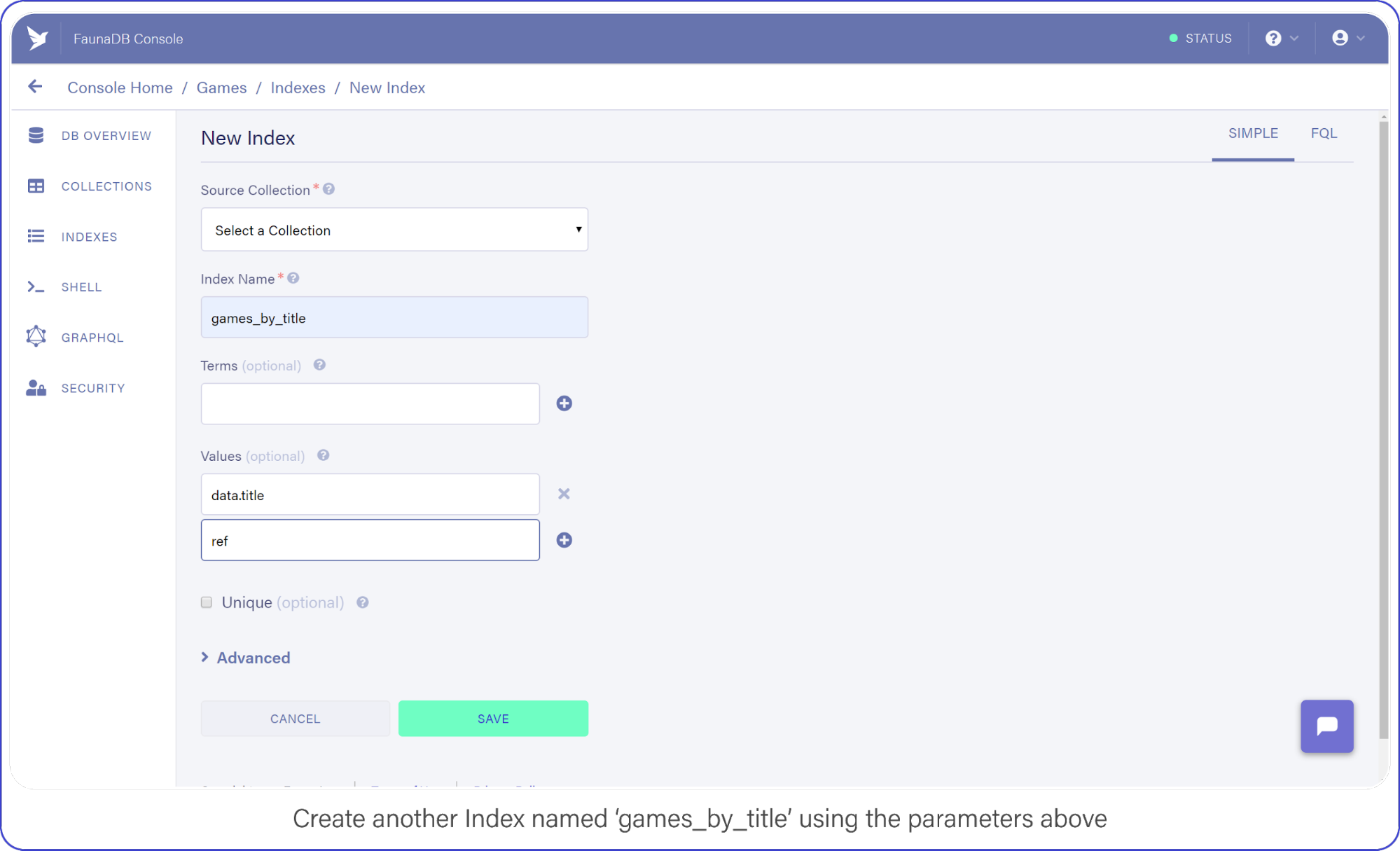
games_by_title using the parameters above.Click "Save" when you’re ready.
Back in index.js, add your fourth and final API call:
api.get(['/api/v1/console/:name', '/api/v1/console/:name/'], (req, res) => {...})
api.get(['/api/v1/games/', '/api/v1/games'], (req, res) => {
let findGamesByName = client.query(
q.Map(
q.Paginate(
q.Filter(
q.Match(q.Index('games_by_title')),
q.Lambda(
['title', 'ref'],
q.GT(
q.FindStr(
q.LowerCase(q.Var('title')),
req.query.title.toLowerCase()
),
-1
)
)
)
),
q.Lambda(['title', 'ref'], q.Get(q.Var('ref')))
)
)
findGamesByName
.then(result => {
console.log(result)
res.status(200).send(result)
return
})
.catch(error => {
res.error(error)
})
})Big breath because I know there are many brackets (Lisp programmers will love this) , but once you understand the components, the full query is quite easy to understand since it’s basically just like coding.
Beginning with the first new function you spot, Filter. Filter is again very similar to the filter you encounter in programming languages. It reduces an Array or Set to a subset based on the result of a Lambda function.
In this Filter, you exclude any game titles that do not contain the user’s search query.
You do that by comparing the result of FindStr (a string finding function similar to JavaScript’s indexOf) to -1, a non-negative value here means FindStr discovered the user’s query in a lowercase-version of the game’s title.
And the result of this Filter is passed to Map, where each document is retrieved and placed in the final result output.
Now you may have thought the obvious: performing a string comparison across four entries is cheap, 2 million…? Not so much.
This is an inefficient way to perform a text search, but it will get the job done for the purpose of this example. (Maybe we should have used ElasticSearch or Solr for this?) Well in that case, FaunaDB is quite perfect as central system to keep your data safe and feed this data into a search engine thanks to the temporal aspect which allows you to ask Fauna: “Hey, give me the last changes since timestamp X?”. So you could setup ElasticSearch next to it and use FaunaDB (soon they have push messages) to update it whenever there are changes. Whoever did this once knows how hard it is to keep such an external search up to date and correct, FaunaDB makes it quite easy.
Test the API by searching for "Halo":
$ curl http://localhost:5000/api/v1/games?title=haloDon’t You Dare Forget This One Firebase Optimization
A lot of Firebase Cloud Functions code snippets make one terribly wrong assumption: that each function invocation is independent of another.
In reality, Firebase Function instances can remain "hot" for a short period of time, prepared to execute subsequent requests.
This means you should lazy-load your variables and cache the results to help reduce computation time (and money!) during peak activity, here’s how:
let functions, admin, faunadb, q, client, express, cors, api
if (typeof api === 'undefined') {
... // dump the existing code here
}
exports.api = functions.https.onRequest(api)Deploy Your REST API with Firebase Functions
Finally, deploy both your functions and hosting configuration to Firebase by running firebase deploy from your shell.
Without a custom domain name, refer to your Firebase subdomain when making API requests, e.g. https://{project-name}.firebaseapp.com/api/v1/.
What Next?
FaunaDB has made me a conscientious developer.
When using other schemaless databases, I start off with great intentions by treating documents as if I instantiated them with a DDL (strict types, version numbers, the whole shebang).
While that keeps me organized for a short while, soon after standards fall in favor of speed and my documents splinter: leaving outdated formatting and zombie data behind.
By forcing me to think about how I query my data, which Indexes I need, and how to best manipulate that data before it returns to my server, I remain conscious of my documents.
To aid me in remaining forever organized, my catalog (in FaunaDB Console) of Indexes helps me keep track of everything my documents offer.
And by incorporating this wide range of arithmetic and linguistic functions right into the query language, FaunaDB encourages me to maximize efficiency and keep a close eye on my data-storage policies. Considering the affordable pricing model, I’d sooner run 10k+ data manipulations on FaunaDB’s servers than on a single Cloud Function.
For those reasons and more, I encourage you to take a peek at those functions and consider FaunaDB’s other powerful features.
The post Build a 100% Serverless REST API with Firebase Functions & FaunaDB appeared first on CSS-Tricks.