Going Buildless
Publikováno: 27.8.2019
I'm in a long distance relationship. That means I’m on a plane to England every few weeks, and every time I'm on that plane, I think about how nice it would be to read some Reddit posts. What I could do is find a Reddit app that lets me cache posts for offline (I’m sure there is one out there), or I could take the opportunity to write something myself and have fun using the latest and greatest technologies and … Read article
The post Going Buildless appeared first on CSS-Tricks.
I'm in a long distance relationship. That means I’m on a plane to England every few weeks, and every time I'm on that plane, I think about how nice it would be to read some Reddit posts. What I could do is find a Reddit app that lets me cache posts for offline (I’m sure there is one out there), or I could take the opportunity to write something myself and have fun using the latest and greatest technologies and web standards out there!
On top of that, there has been a lot of discussion around what I like to call going buildless, which I think is really fascinating development in which production projects are created without using a build process (like a bundler).
This post is also a homage to a couple of awesome people in the web community who are making some great things possible. I'll be linking to all that stuff as we move along. Do note that this won't be a step-by-step tutorial, but if you want to check out the code, you can find the finished project on GitHub.
Our end result should look something like this:
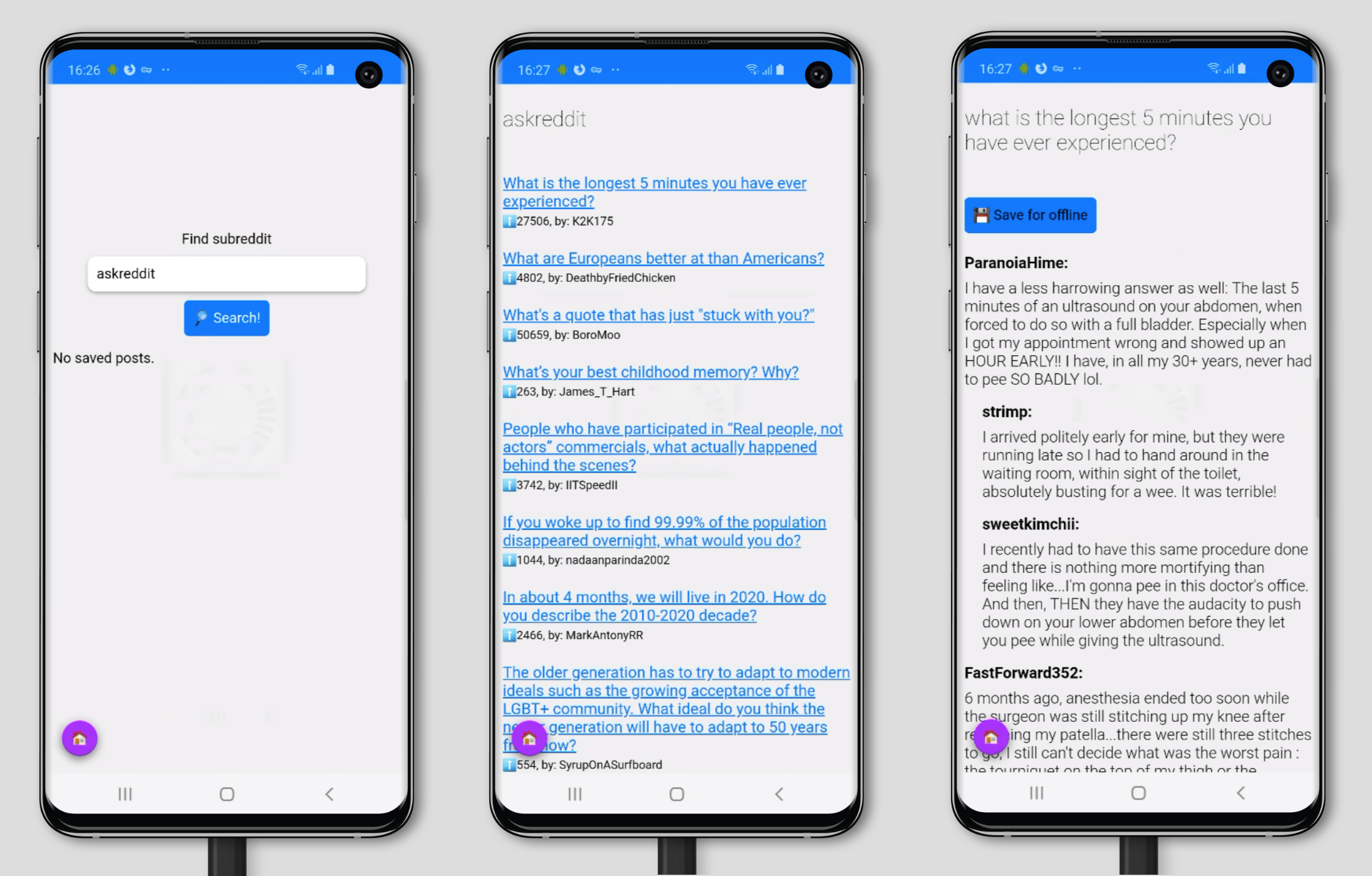
Let's dive in and install a few dependencies
npm i @babel/core babel-loader @babel/preset-env @babel/preset-react webpack webpack-cli react react-dom redux react-redux html-webpack-plugin are-you-tired-yet html-loader webpack-dev-serverI'm kidding.
We're not gonna use any of that.
We're going to try and avoid as much tooling and dependencies as we can to keep the entry barrier low. What we will be using is:
- LitElement - LitElement is our component model. It's easy to use, lightweight, close to the metal, and leverages web components.
- @vaadin/router - This is a really small (< 7kb) router that has an awesome developer experience that I cannot recommend enough.
- @pika/web - This will help us get our modules together for easy development.
- es-dev-server - This is a simple dev server for modern web development workflows, made by us at open-wc. Although any HTTP server will doc, feel free to bring your own.
That's it! We'll also be using a few browser standards, namely: es modules, web components, import-maps, kv-storage and service-worker.
Let's go ahead and install our dependencies:
npm i -S lit-element @vaadin/router
npm i -D @pika/web es-dev-serverWe'll also add a postinstall hook to our package.json that's going to run Pika for us:
"scripts": {
"start": "es-dev-server",
"postinstall": "pika-web"
}🐭 Pika
Pika is a project by Fred K. Schott that aims to bring that nostalgic 2014 simplicity to 2019 web development. Fred is up to all sorts of awesome stuff. For one, he made pika.dev, which lets you easily search for modern JavaScript packages on npm. He also recently gave his talk Reimagining the Registry at DinosaurJS 2019, which I highly recommend you watch.
Pika takes things even one step further. If we run pika-web, it'll install our dependencies as single JavaScript files to a new web_modules/ directory. If your dependency exports an ES "module" entrypoint in its package.json manifest, Pika supports it. If you have any transitive dependencies, Pika will create separate chunks for any shared code among your dependencies.
What this means, is that in our case our output will look something like:
└─ web_modules/
├─ lit-element.js
└─ @vaadin
└─ router.jsSweet! That's it. We have our dependencies ready to go as single JavaScript module files, and this is going to make things really convenient for us later on in this post, so stay tuned!
📥 Import maps
Alright! Now that we've got our dependencies sorted out, let's get to work. We'll make an index.html that'll look something like this:
<html>
<!-- head, etc. -->
<body>
<reddit-pwa-app></reddit-pwa-app>
<script src="./src/reddit-pwa-app.js" type="module"></script>
</body>
</html>And reddit-pwa-app.js:
import { LitElement, html } from 'lit-element';
class RedditPwaApp extends LitElement {
// ...
render() {
return html`
<h1>Hello world!</h1>
`;
}
}
customElements.define('reddit-pwa-app', RedditPwaApp);We're off to a great start. Let's try and see how this looks in the browser so far, so lets start our server, open the browser and... What's this? An error?

Oh boy.
And we've barely even started. Alright, let's take a look. The problem here is that our module specifiers are bare. They are bare module specifiers. What this means is that there are no paths specified, no file extensions, they're just... pretty bare. Our browser has no idea on what to do with this, so it'll throw an error.
import { LitElement, html } from 'lit-element'; // <-- bare module specifier
import { Router } from '@vaadin/router'; // <-- bare module specifier
import { foo } from './bar.js'; // <-- not bare!
import { html } from 'https://unpkg.com/lit-html'; // <-- not bare!Naturally, we could use some tools for this, like webpack, or rollup, or a dev server that rewrites the bare module specifiers to something meaningful to browsers, so we can load our imports. But that means we have to bring in a bunch of tooling, dive into configuration, and we're trying to stay minimal here. We just want to write code! In order to solve this, we're going to take a look at import maps.
Import maps is a new proposal that lets you control the behavior of JavaScript imports. Using an import map, we can control what URLs get fetched by JavaScript import statements and import() expressions, and allows this mapping to be reused in non-import contexts. This is great for several reasons:
- It allows our bare module specifiers to work.
- It provides a fallback resolution so that
import $ from "jquery";can try to go to a CDN first, but fall back to a local version if the CDN server is down. - It enables polyfilling of (or other control over) built-in modules. (More on that later, hang on tight!)
- Solves the nested dependency problem. (Go read that blog!)
Sounds pretty sweet, no? Import maps are currently available in Chrome 75+ behind a flag, and with that knowledge in mind, let's go to our index.html, and add an import map to our <head>:
<head>
<script type="importmap">
{
"imports": {
"@vaadin/router": "/web_modules/@vaadin/router.js",
"lit-element": "/web_modules/lit-element.js"
}
}
</script>
</head>If we go back to our browser, and refresh our page, we'll have no more errors, and we should see our <h1>Hello world!</h1> on our screen.
Import maps is an incredibly interesting new standard, and definitely something you should be keeping your eyes on. If you're interested in experimenting with them, and generate your own import map based on a yarn.lock file, you can try our open-wcimport-maps-generate package and play around. Im really excited to see what people will develop in combination with import maps.
📡 Service Worker
Alright, we're going to skip ahead in time a little bit. We've got our dependencies working, we have our router set up, and we've done some API calls to get the data from Reddit and display it on our screen. Going over all of the code is a bit out of scope for this post, but remember that you can find all the code in the GitHubrepo if you want to read the implementation details.
Since we're making this app so we can read reddit threads on the airplane it would be great if our application worked offline, and if we could somehow save some posts to read.
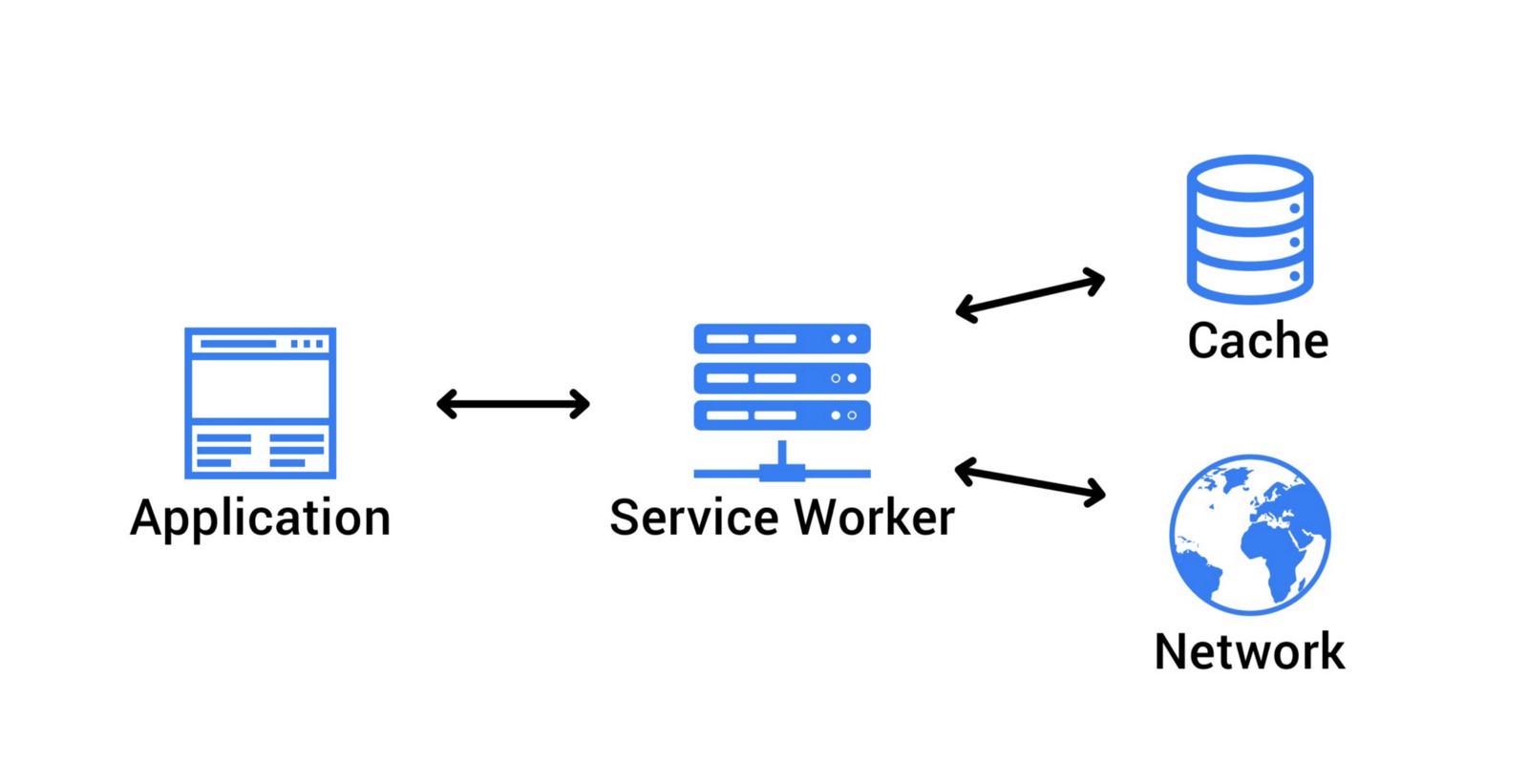
Service workers are a kind of JavaScript Worker that runs in the background. You can visualize it as sitting in between the web page, and the network. Whenever your web page makes a request, it goes through the service worker first. This means that we can intercept the request, and do stuff with it! For example, we can let the request go through to the network to get a response, and cache it when it returns so we can use that cached data later when we might be offline. We can also use a service worker to precache our assets. What this means is that we can precache any critical assets our application may need in order to work offline. If we have no network connection, we can simply fall back to the assets we cached, and still have a working (albeit offline) application.
If you're interested in learning more about Progressive Web Apps and service worker, I highly recommend you read The Offline Cookbook, by Jake Archibald, as well as this video tutorial series by Jad Joubran.
Let's go ahead and implement a service worker. In our index.html, we'll add the following snippet:
<script>
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker.register('./sw.js').then(() => {
console.log('ServiceWorker registered!');
}, (err) => {
console.log('ServiceWorker registration failed: ', err);
});
});
}
</script>We'll also add a sw.js file to the root of our project. So we're about to precache the assets of our app, and this is where Pika just made life really easy for us. If you'll take a look at the install handler in the service worker file:
self.addEventListener('install', (event) => {
event.waitUntil(
caches.open(CACHENAME).then((cache) => {
return cache.addAll([
'/',
'./web_modules/lit-element.js',
'./web_modules/@vaadin/router.js',
'./src/reddit-pwa-app.js',
'./src/reddit-pwa-comment.js',
'./src/reddit-pwa-search.js',
'./src/reddit-pwa-subreddit.js',
'./src/reddit-pwa-thread.js',
'./src/utils.js',
]);
})
);
});You'll find that we're totally in control of our assets, and we have a nice, clean list of files we need in order to work offline.
📴 Going offline
Right. Now that we've cached our assets to work offline, it would be excellent if we could actually save some posts that we can read while offline. There are many ways that lead to Rome, but since we're living on the edge a little bit, we're going to go with: Kv-storage!
📦 Built-in Modules
There are a few things to talk about here. Kv-storage is a built-in module. Built-in modules are very similar to regular JavaScript modules, except they ship with the browser. It's good to note that while built-in modules ship with the browser, they are not exposed on the global scope, and are namespaced with std: (Yes, really.). This has a few advantages: they won't add any overhead to starting up a new JavaScript runtime context (e.g. a new tab, worker, or service worker), and they won't consume any memory or CPU unless they're actually imported, as well as avoid naming collisions with existing code.
Another interesting, if not somewhat controversial, proposal as a built-in module is the std-toast element, and the std-switch element.
🗃 Kv-storage
Alright, with that out of the way, lets talk about kv-storage. Kv-storage (or "key value storage") is layered on top of IndexedDB and fairly similar to localStorage, except for only a few major differences.
The motivation for kv-storage is that localStorage is synchronous, which can lead to bad performance and syncing issues. It's also limited exclusively to String key/value pairs. The alternative, IndexedDB, is... hard to use. The reason it's so hard to use is that it predates promises, and this leads to a, well, pretty bad developer experience. Not fun. Kv-storage, however, is a lot of fun, asynchronous, and easy to use! Consider the following example:
import { storage, /* StorageArea */ } from "std:kv-storage";
(async () => {
await storage.set("mycat", "Tom");
console.log(await storage.get("mycat")); // Tom
})();Notice how we're importing from std:kv-storage? This import specifier is bare as well, but in this case it's okay because it actually ships with the browser.
Pretty neat. We can perfectly use this for adding a 'save for offline' button, and simply store the JSON data for a Reddit thread, and get it when we need it.
// reddit-pwa-thread.js:52:
const savedPosts = new StorageArea("saved-posts");
// ...
async saveForOffline() {
await savedPosts.set(this.location.params.id, this.thread); // id of the post + thread as json
this.isPostSaved = true;
}So now if we click the “save for offline" button, and we go to the DevTools “Application" tab, we can see a kv-storage:saved-posts that holds the JSON data for this post:
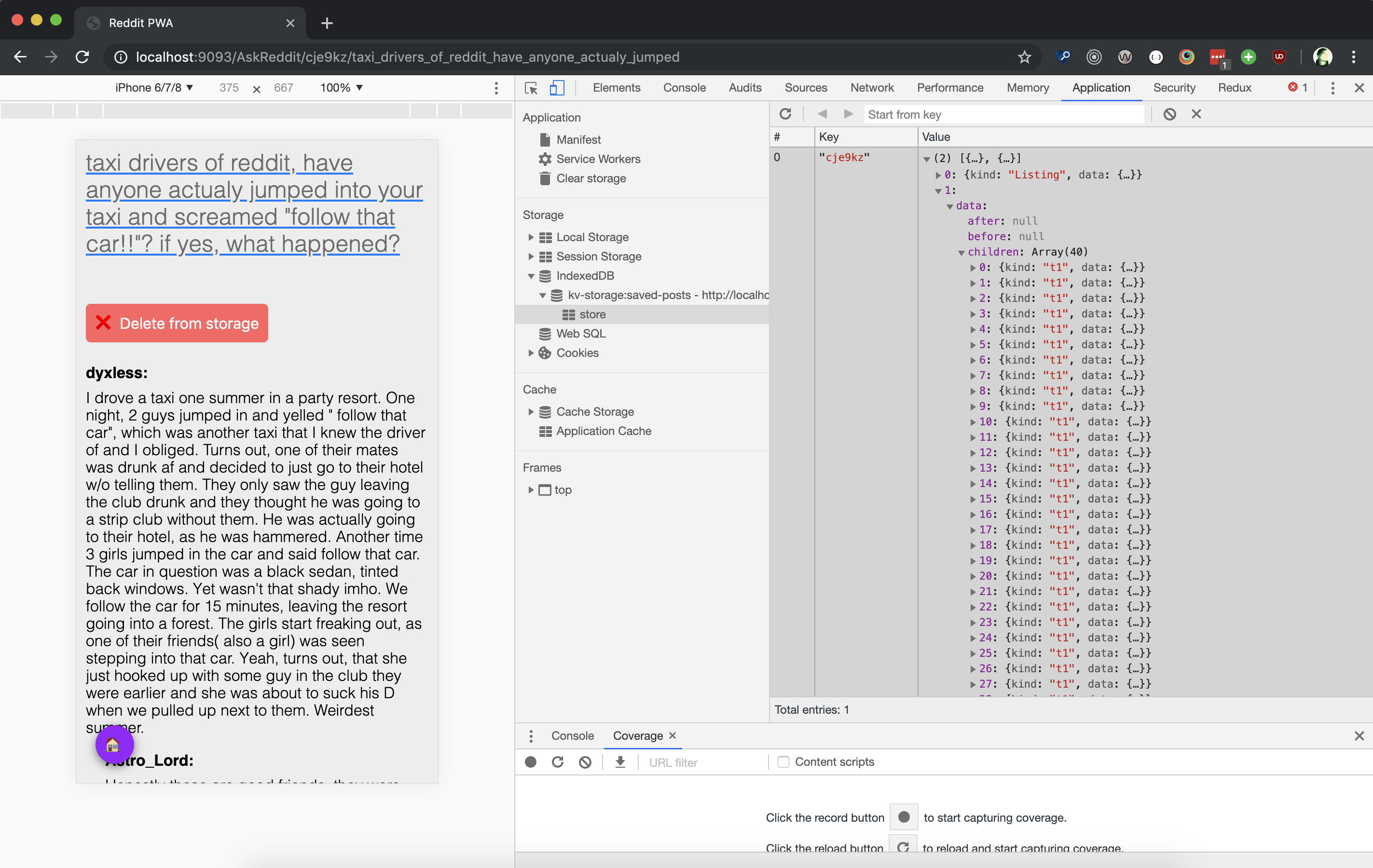
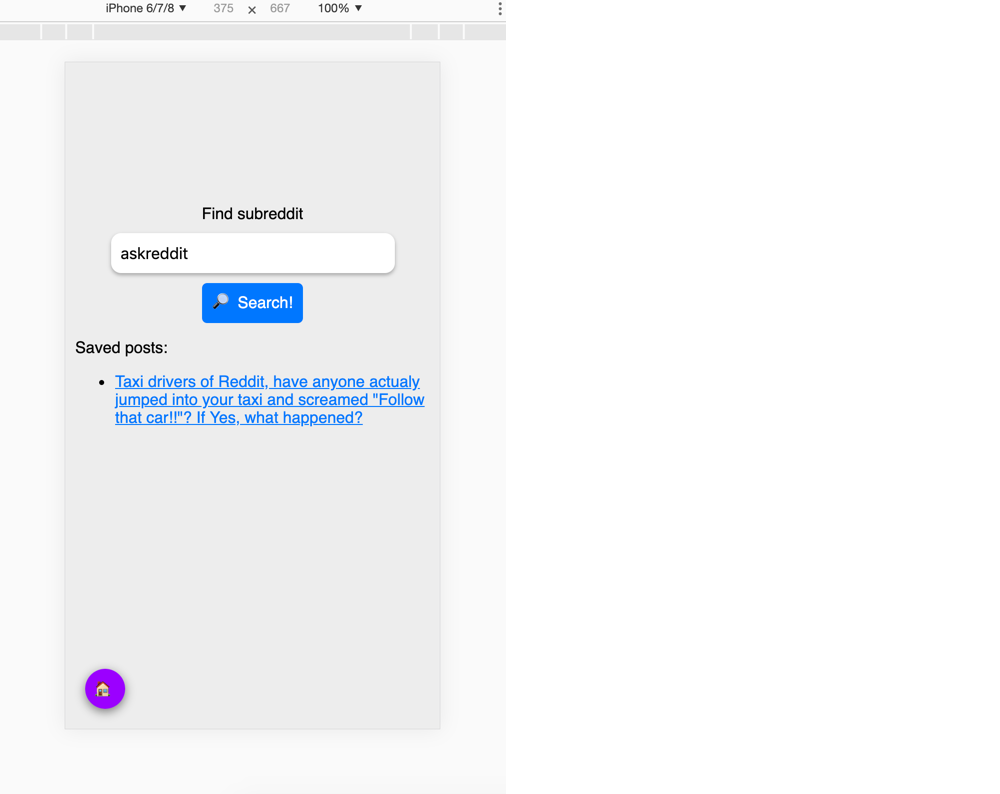
And if we go back to our search page, we'll have a list of saved posts with the post we just saved:
🔮 Polyfilling
Excellent. However, we're about to run into another problem here. Living on the edge is fun, but also dangerous. The problem that we're hitting here is that, at the time of writing, kv-storage is only implemented in Chrome behind a flag. That's not great. Fortunately, there's a polyfill available, and at the same time we get to show off yet another really useful feature of import-maps; polyfilling!
First things first, lets install the kv-storage-polyfill:
npm i -S kv-storage-polyfillNote that our postinstall hook will run Pika for us again.
Let’s also add the following to our import map in our index.html:
<script type="importmap">
{
"imports": {
"@vaadin/router": "/web_modules/@vaadin/router.js",
"lit-element": "/web_modules/lit-element.js",
"/web_modules/kv-storage-polyfill.js": [
"std:kv-storage",
"/web_modules/kv-storage-polyfill.js"
]
}
}
</script>What happens here is that whenever /web_modules/kv-storage-polyfill.js is requested or imported, the browser will first try to see if std:kv-storage is available; however, if that fails, it'll load /web_modules/kv-storage-polyfill.js instead.
So in code, if we import:
import { StorageArea } from '/web_modules/kv-storage-polyfill.js';This is what will happen:
"/web_modules/kv-storage-polyfill.js": [ // when I'm requested
"std:kv-storage", // try me first!
"/web_modules/kv-storage-polyfill.js" // or fallback to me
]🎉 Conclusion
And we should now have a simple, functioning PWA with minimal dependencies. There are a few nitpicks to this project that we could complain about, and they'd all likely be fair. For example, we probably could've gone without using Pika, but it does make life really easy for us. You could have made the same argument about adding a webpack configuration, but you'd have missed the point. The point here is to make a fun application, while using some of the latest features, drop some buzzwords, and have a low barrier for entry. As Fred Schott would say: "In 2019, you should use a bundler because you want to, not because you need to."
If you're interested in nitpicking, however, you can read this great discussion about using webpack vs. Pika vs. buildless, and you'll get some great insights from Sean Larkinn of the webpack core team himself, as well as Fred K. Schott, creator of Pika.
I hope you enjoyed this blog post, and I hope you learned something, or discovered some new interesting people to follow. There are lots of exciting developments happening in this space right now, and I hope I got you as excited about them as I am. If you have any questions, comments, feedback, or nitpicks, feel free to reach out to me on twitter at @passle_ or @openwc and don't forget to check out open-wc.org 😉.
Honorable Mentions
I'd like to give a few shout-outs to some very interesting people that are doing some great stuff, and you may want to keep an eye on.
- Guy Bedford, who wrote es-module-shims, which, well, shims ES modules, and import maps. Which if you ask me is quite an amazing feat, and allows me to actually use some of these new technologies that aren't implemented on all browsers yet.
- Luke Jackson's talk Don't Build That App! No webpack, no worries 🤓🤙, as Luke would say.
- Thanks to Benny Powers and Lars den Bakker for their helpful comments and feedback.
The post Going Buildless appeared first on CSS-Tricks.