Fluentd, case study
Publikováno: 19.5.2021
Text vyšel původně na autorově webu.
Pamatujete si na film Inception? Šlo o to, že ve snu se odehrává sen, ve kterém se odehrává sen a něm… se odehrává sen. Tak něco podobného jsem implementoval ve Fluentd.
Jak už jsem psal v úvodu této minisérie o Fluentd (viz články Fluentd, budoucnost logování a Lehký úvod do Fluentd), dostal jsem se k této technologii v rámci práce na novém produktu. Nebudu ho jmenovat, ale zaměřím se na statickou architekturu a jak na ní aplikovat Fluentd.
Technický popis produktu
Byznysově spadá nejmenovaný produktu od oblasti infrastrukturní nativní cloudové služby na pomezí IaaS a PaaS. Jak je u cloudových služeb běžné, je nejmenovaný produkt rozdělen na dvě části Control Plane a Data Plane. Inkriminovaná část, která používá Fluentd spadá do Data Plane
Poznámka pro ne-cloudové lidi: Control Plane se stará o vytváření a lifecycle instancí Data Plane. Data Plane pak dělá samotný business.
Proč jsem v úvodu zmiňoval film Inception? Protože tahle část nejmenovaného produktu je ve skutečnosti compute postavený na computu. Navíc proložený Kubernetes.
Poznámka pro ne-cloudové lidi: Compute je infrastruktura v cloudu, která poskytuje výpočetní výkon.
Základní jednotkou našeho computu je něco, čemu říkáme cell, buňka. (Pro potřeby článku není podstatné, co cell počítá.) Cell je bezstavová aplikace, která běží v Docker kontejneru. Kontejnery běží v Kubernetes. Kubernetes nody běží na standardním cloudovém computu (provider není důležitý).
Zatím mě stačíte sledovat? Pojďme dál, protože to ještě není tak složitý. Důležité jsou tři věci:
- Důvodem existence cell je paralelizace výpočtu a agregace výsledků.
- Popisované řešení je multitenant.
- Řešení používá autoscale.
To má důležité implikace, ale pro náš technický popis je podstatné, že to vede k mnohočetným Kubernetes clusterům. Zároveň je potřeba říct, že instance cell (resp. daný Docker kontejner) může vzniknout v (téměř) libovolném clusteru a samozřejmě, pokud se kontejner s cell z nějakého důvodu restartuje, může ho Kubernetes nově instancovat na libovolném nodu daného clusteru. No a autoscale způsobuje, že cell dynamicky vznikají a zanikají.
Poslední dílek do skládačky je kvantitativní velikost řešení. Bavíme se o stovkách až tisících cell rozložených v jednotkách clusterů v rámci jednoho cloud regionu. Jen pro představu, naše vývojářské testovací prostředí má momentálně ve 2 clusterech cca 400 nodů.
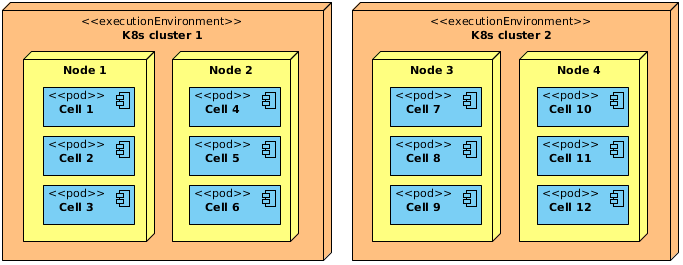
Design Fluentd řešení
Teď, když víme, v jaké škále a v jakém designu nám běží všechny cell, je úkol Fluentd přímočarý — posbírat všechny logy ze všech clusterů. Schválně říkám “všechny logy”. Protože v tom Kubernetes neběží jen cell, ale i další kontejnery, které podporují dané řešení — ať už jako sidecars běžící ve stejném podu jako cell, nebo jako daemon set běžící na daném nodu clusteru.
Poznámka pro ne-kubernetes lidi: daemon set je pod, který běží na daném nodu pouze jednou. Pod je nejmenší deployment jednotka, kterou Kubernetes spravuje.
Jelikož všichni rádi logují do souborů, vydali jsme se touhle cestou — všechny log soubory jsou namapovány do nějakého adresáře na daném Kubernetes nodu. U daemon setů je to mapování 1:1. U ostatních podů je to mapování do adresářové struktury — každá cell má svoje ID a (její kontejner) mapuje log do adresáře s názvem tohoto ID. Například cell s ID cell-v1-42 mapuje do adresáře /tmp/cells/cell-v1-42.
Fluentd běží na daném nodu jako daemon set a pomocí tail pluginu sleduje všechny tyto log soubory a dále je zpracovává. Velkou výhodou tail pluginu je, že kromě jednotlivých souborů umí zpracovávat soubory v hierarchické adresářové struktuře. 
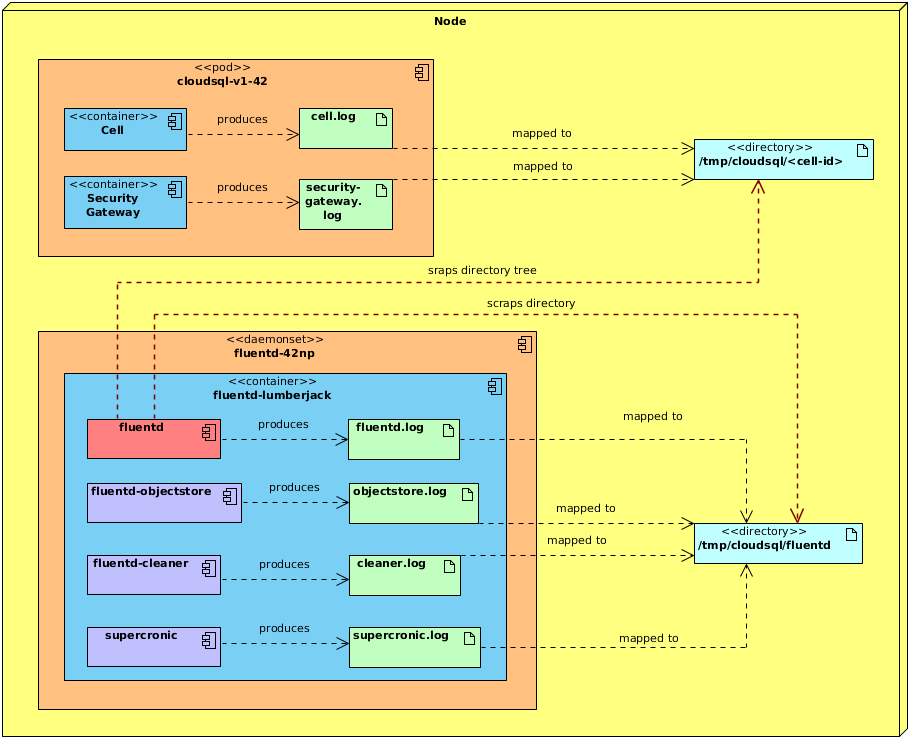
Co v tomto článku pominu, jsou použité output pluginy, protože to není nijak zajímavé, ani zprostředkovatelné — výstupním systémem je proprietární řešení, které nebudu popisovat, ale vy si tam můžete představit Elasticsearch.
Filter pluginy také více méně přeskočím, krátce je zmíním v sekci Problémy.
Problémy
Samozřejmě, jedním ze základních problémů v distribuovaném prostředí je reliability (a s ním často související final consistency). Pro Fluentd, zrozeném v cloudovém paradigmatu, to není žádný problém — out-of-the-box má zabudovaný štědrý retry mechanizmus s exponential backoff sekvencí.
OK, jeden problém vyřešen, ale místo něj máme hned dva další: 1) jak zjistit, že dochází k opakovanému volání cílové platformy a 2) jaká chyba ho způsobuje? Bod číslo jedna má jednoduchou odpověď — monitoring (viz další sekce) a na něj navázané alerty.
Bod číslo dva záleží na prostředí — u výše popsaného řešení to znamenalo hlavně být schopný:
- získat logy pro daný pod a daemon set,
- být fluent v
kubectla umět debuggovat v Kubernetes, - dohledat konkrétní node a přes
sshudělat lokální investigaci.
Ladění bufferu
Konkrétní problém, který jsem řešil v této oblasti, bylo jednak odmítání logů cílovým systémem a jednak jeho zahlcení počtem requestů. Fluentd odesílá logy v tzv. chunks. Kromě toho, že byla výchozí velikost chunku příliš veliká, tak se také posílaly v příliš velkých dávkách. Ohledně velikosti to chce trochu experimentovat, protože vy zpravidla víte počet vstupních řádků, ale nevíte velikost v bytech. Navíc ve výstupních chuncích můžou být data v jiném formátu, či různě odekorovaná.
Velikost chunku ale není všechno. Dalším důležitým parametrem je nastavení odesílání (flushing), tedy jak často se buffer vyprázdní a v kolika threadech odesílání probíhá. Aby toho nebylo málo, je dobré se zamyslet nad typem bufferu — paměť, nebo soubor. Je tam mimo jiné velký rozdíl v maximální velikosti bufferu (8 MB vs. 50 MB).
Ve finále jsem skončil s nastavováním parametrů chunk_limit_size, queue_limit_length, flush_interval a flush_thread_count. (Konkrétní hodnoty zde neuvádím, protože bez znalosti daného prostředí nedávají smysl.)

Sanitizace záznamů
Další problém, který jsem řešil, byl v chybně formátovaných a nevalidních (originálních) logovacích záznamech, tedy těch, které produkovala přímo ona zmíněná aplikace, cell. Pominu takové drobnosti, jako chybně zformátované datum, či nesoulad mezi unix timestamp a timestamp v milisekundách.
Zajímavější byl případ nezpracovaných chunků, které chyběly v cílové systému. To bylo docela kuriózní, protože vývojáři oné cell byli low level C-čkaři (do morku kostí), zcela nepolíbení cloudem a distribuovanými systémy a tak se občas a náhodně stávalo, že thread zapisující do logu spadnul před ukončením zápisu a v logu tak byly zapsány nevalidní znaky. To se tak stává, když do souboru zapíšety místo 8 bitů třeba jen 4 nebo 5.
Na úrovni Fluentd je potřeba to řešit na dvou úrovních — jednak, aby to tail plugin vůbec načetl a jednak, jak to ošetřit dál v pipeline. V prvním případě jde o to, jak tolerantní je JSON parser. Záleží na vaší instalaci Fluentd, jaký Ruby JSON parser se používá — občas si můžete v logu Fluentd povšimnout hlášky:
Oj is not installed, and falling back to Yajl for json parserOj a Yajl jsou dva Ruby parsery. Nijak se v tom nevyznám, který z nich je lepší, či vhodnější, ale vzhledem k mému problému — Oj byl schopný invalidní znaky načíst, zatímce Yajl ne (prostě spadnul). Pomoc je jednoduchá — nainstaloval buď Oj, nebo ruby-bigdecimal. Viz také Fluentd FAQ.
Jak vyřešit druhý případ jsem naznačil ve minulém díle tohoto miniseriálu — stačí zapojit filter plugin a nevalidní znaky odfiltrovat, nahradit apod.
<filter cloudsql.cell.app>
@type record_transformer
enable_ruby
<record>
msg ${record["msg"].encode("UTF-8", invalid: :replace, replace: "__NON_ASCII_CHAR__")}
</record>
</filter>Zálohování chunků
Třetí záležitost, kterou jsem řešil, nebyl problém sám o sobě, ale spíš optimalizace vyhledávání a prozkoumávání chyb. Pokud mi vývojáři cell nahlásili, že v cílovém systému (pravděpodobně) chybí “nějaké logy”, znamenalo to zdlouhavou investigaci. Ve snaze zkrátit tento čas bylo primární zjistit, zda cell daný log v první řadě vůbec vyprodukovala.
Přišel jsem tedy s řešením — v rámci debug módu — zálohovat “raw” logy a jejich chunky na object storage a v případě problému dané logy stáhnout a progrepovat. Celým technickým řešením se zde nebudu zabývat, jen zmíním implementaci týkající se Fluentd — chunky čekající na odeslání jsem zálohoval pomocí exec pluginu, kterým jsem provolával jednoduchou CLI aplikaci (napsanou v Golangu), která pomocí SDK daného object storage řešení ukládala chunky do zvoleného bucketu.
<match cloudsql.cell.app>
@type exec
command /fluentd/bin/fluentd-objectstore
<format>
@type json
</format>
<buffer>
@type file
path /var/log/fluentd-buffers/objectstore.buffer
flush_interval 10s
chunk_limit_size 100MB
compress gzip
</buffer>
</match>Monitoring
Monitoring Fluentd by si zasloužil samostatný článek, ale já už bych rád tenhle miniseriálek ukončil, takže to vezmu hopem.
Synonymem pro monitoring v cloudu je Prometheus, který je, tak jako Fluentd, graduovaným CNCF projektem. Fluentd nabízí Prometheus plugin, který se dá jednoduše zprovoznit a nakonfigurovat, viz dokumentace Monitoring by Prometheus. Tím dostaneme zadarmo spoustu prometheovských metrik, otázka zní, které z nich jsou (pro troubleshooting) důležité. Ty, které jsem sledoval já, jsou následující:
fluentd_input_status_num_records_totalpočet vstupních záznamů,fluentd_output_status_num_records_totalpočet výstupních záznamů,fluentd_output_status_num_errorspočet výstupních chyb (při volání cílového systému),fluentd_output_status_buffer_queue_lengthdélka fronty pro buffer,fluentd_output_status_retry_countpočet opakovaných volání po výstupní chybě.
To, že Fluentd vystavuje metriky samozřejmě nestačí — je potřeba metriky sbírat, agregovat, vizualizovat a v případě problému, spustit alarm. Na sbírání metrik je ideální… Prometheus  . Jak přesně bude vypadat architektura sbírání metrik je závislé na prostředí a návazných systémech, takže nelze poradit ideální řešení.
. Jak přesně bude vypadat architektura sbírání metrik je závislé na prostředí a návazných systémech, takže nelze poradit ideální řešení.
V našem případě bylo cílové prostředí pro metriky proprietární, takže jsem skončil s řešením, kdy byl Prometheus deployovaný jako daemon set v jednom podu s Fluentd a ještě další aplikací, která překládala metriky pro cílový systém a taky je do něj publikovala. A na vizualizaci obligátní Grafana. Alarmy opět proprietární, nicméně prometheovské alerty jsou víc než dostačující.
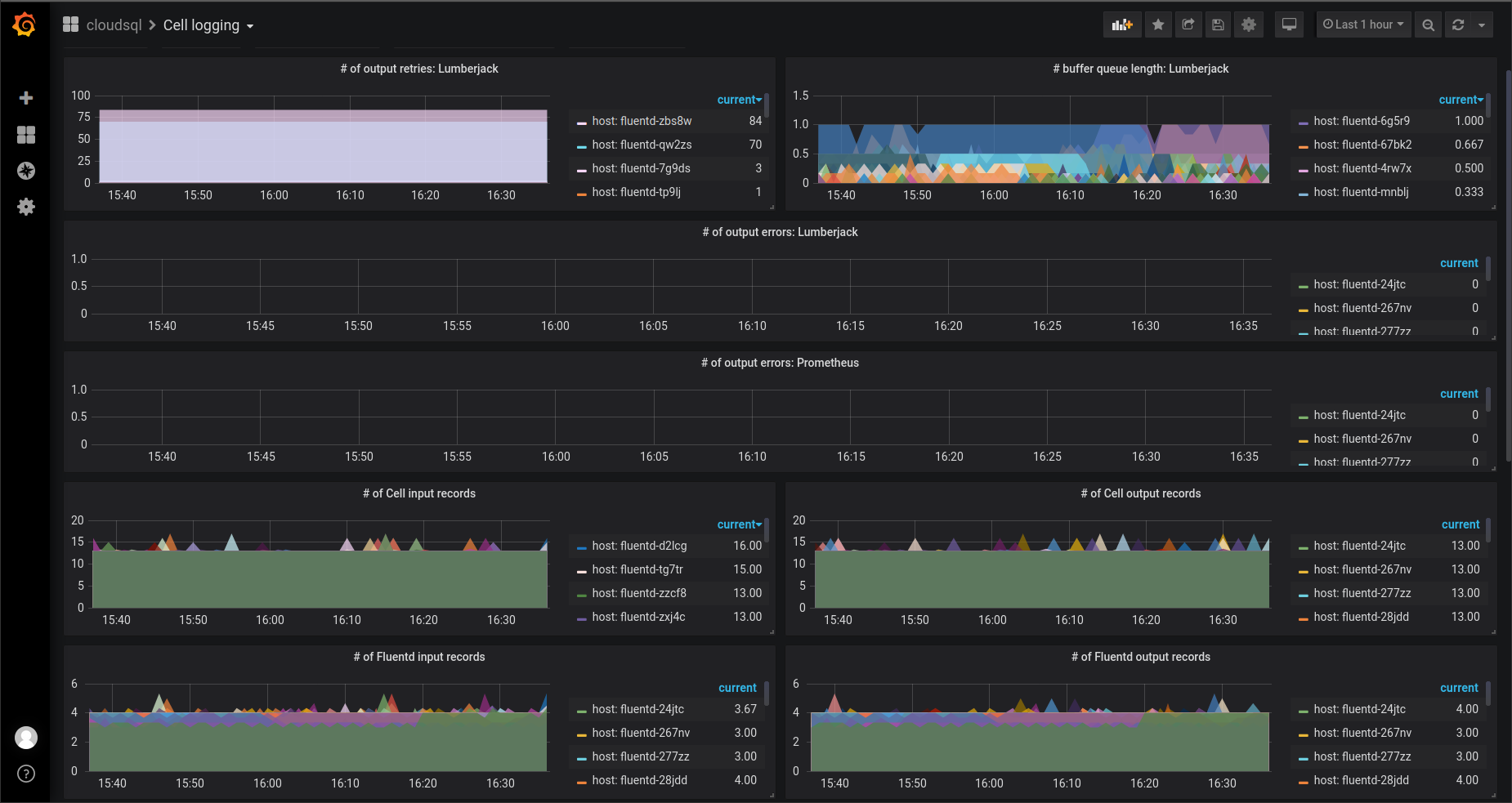
Závěr
Výše popsané řešení jsem více méně full time implementoval, ladil a vylepšoval zhruba dva měsíce. Po skončení této periody musím říct, že Fluentd je vhodné technické řešení pro daný use case, out-of-the-box má spoustu vhodných nástrojů a co se týká performance, bez problémů a spolehlivě zvládá zpracovat desítky GB logů denně v netriviálním distribuovaném prostředí.
Vlastně jsem zatím nenarazil na žádný problém, který by nebyl řešitelný skrze dostupné pluginy, či pomocí podpůrných koexistujících aplikací. Na druhou stranu, kdyby se vyskytl zásadní problém, který by vyžadoval implementaci nativního pluginu napsaného v Ruby, do toho by se mi moc nechtělo. Škoda že Fluentd není napsané v Golangu — myslím, že by tím byl svět cloudových vývojářů o něco jednodušší a přívětivější.