Používáme knihovnu Readability na serveru
Publikováno: 4.4.2019
Možná znáte Readability z reader-view v prohlížeči. Odstraní ze stránky přebytečný balast a zůstane jen dobře čitelný text. Stejný projekt lze s úspěchem použít i na serveru. Pojďme si ukázat, proč i servery potřebují dobře čitelné texty.
Knihovnu readability najdete na GitHubu. Jedná se o javascriptový projekt, který je součástí prohlížeče Firefox. Základní použití je opravdu jednoduché:
var article = new Readability(document).parse();Proč jsme použili readability na serveru?!
Pro náš projekt symptoma.com potřebujeme zpracovávat medicínské texty dostupné na internetu. V textech pak hledáme nemoci, symptomy, medikamenty a jejich souvislosti.
Abychom mohli kvalitně zpracovát text ze stránky, je potřeba jej očistit od zbytečneho balastu, jako je hlavička, menu, navigační prvky, patička. Zajimá nás jen samotný čistý text a metadata článku – tedy titulek, hlavní nadpis, jazyk textu.
Takovy očištěný text je pak třeba navíc zbavit HTML značek. Zbyde jen obsah, zajimavý pro následné zpracovaní – fulltextové vyhledavání, generovaní vystřižků textu, data mining.
Během úvodních testů a brainstormingu jsme náhodou použili reader view ve Firefoxu. A výsledek byl přesně to, co očekaváme:
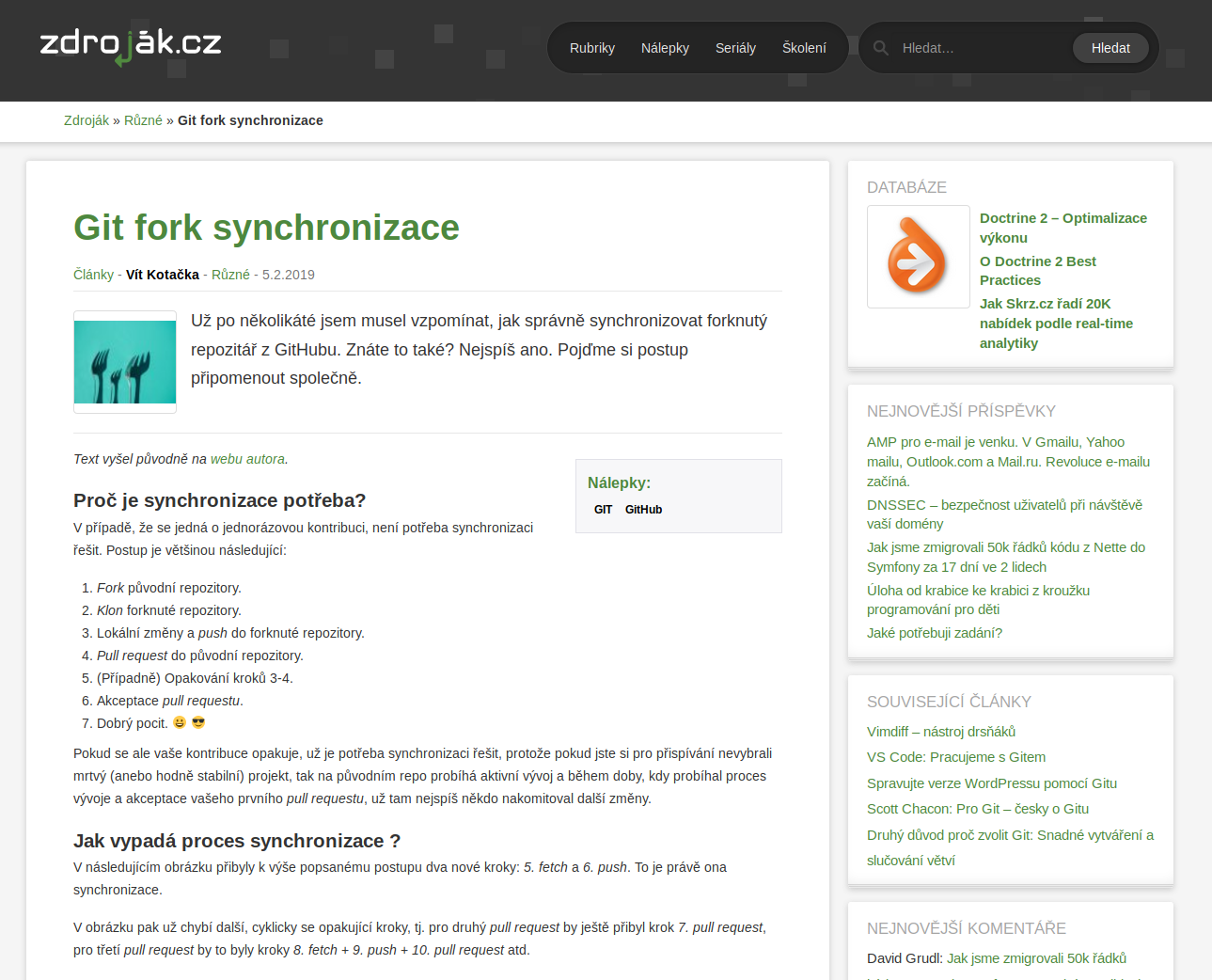
Stránka před zpracováním readability
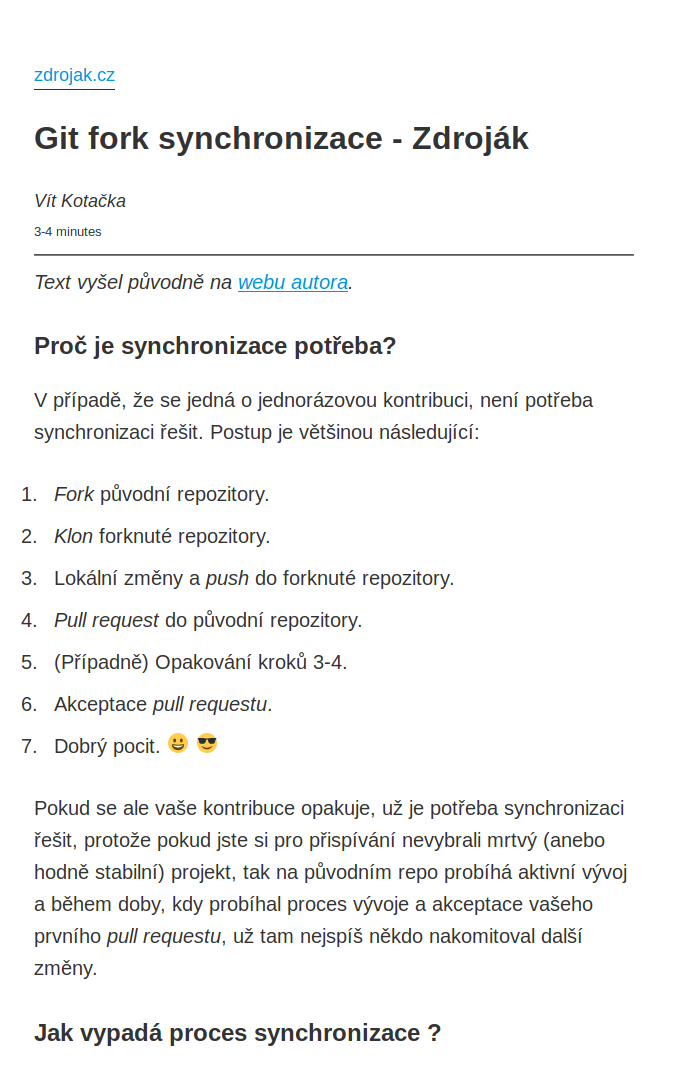
Stránka po zpracování readability
Trocha historie
Readability s tímto názvem a podobnou funkcionalitou vzniklo jako bookmarket, javascriptový kód vložený do záložky v prohlížeči, v roce 2009. Script odstranil přebytečný obsah a upravil CSS styly pro lepší čitelnost. Funkcionalita byla tak od počátku velmi podobná té, jak ji známe dnes. Později autoři přetvořili Readability projekt na webovou službu, s předplatným, mobilními aplikacemi a kdečím. Readability tak ztratilo hodně na kráse a jednoduchosti při snaze o monetizaci. Původní projekt i služba nakonec zanikl roku 2016.
Původní myšlenka Readability byla ale natolik dobrá, že se do prohlížečů vrátila jako nativní funkce. Jedno kliknutí a čitelná verze článku je k dispozici.
Jak integrovat
Protože je naše aplikace postavená na Javě, první pokusy jsme prováděli s karussell/snacktory. Implementace poskytuje čistý text, obdobně jako Readability. Knihovna ale zdaleka nedosahuje kvalit reader-view z Firefoxu. Často selhala detekce hlavního obsahu a výsledky nestály za moc. Navíc nebylo možné rychle otestovat stránku v prohlížeči a očekávat stejné výsledky na serveru.
Nezbylo tedy, nez sáhnout po implementaci mozilla/readability. Mozilla má knihovnu napsanou v JavaScriptu. To pro nás znamenalo vyčlenit celou logiku jako microservice do vlastní aplikace, která poběží na Node.js v Dockeru. Hlavní aplikace s ní pak komunikuje pomoci REST API. Vstupem je jen URL stránky, výstupem pak metadata a čistý text hlavního obsahu.
Striktní oddělení nám také uvolnilo ruce pro škálování, nezávislý vývoj microservice, snadné přidávání nových funkcí, které samotné readability neumí – načtení dokumentu z internetu, detekce a převádění kódování (jschardet, iconv-lite), detekce jazyka z HTML atributů, ověřování robots.txt a robots/noindex meta atributů (naše mikroservice respektuje pravidla), metadata obrázků v hlavním obsahu.
Instalace
Protože mozilla/readability není publikováno jako package na npmjs, je třeba poradit si jinak.
Naštestí má samotný github projekt všechny náležitosti npm modulu a můžeme tak knihovnu nalinkovat přímo z githubu:
"dependencies": {
"readability": "github:mozilla/readability#c0c097c930c8e17969a9ecc143792daf799b215d",
}
Namísto běžné semver verze pak linkujete přímo hash commitu, který chcete použít.
Import třídy je pak také poněkud přes ruku:
const Readability = require('./node_modules/readability/index').Readability;
Pak už vše běží přesně podle ukázek v dokumentaci. Zhruba takováhle data a strukturu můžete očekávat (content jsem pro přehlednost zkrátil).
{
"uri": {
"spec": "https://www.zdrojak.cz/clanky/git-fork-synchronizace/",
"host": "www.zdrojak.cz",
"prePath": "https://www.zdrojak.cz",
"scheme": "https",
"pathBase": "https://www.zdrojak.cz/clanky/git-fork-synchronizace/"
},
"title": "Git fork synchronizace - Zdroják",
"byline": "Vít Kotačka",
"dir": null,
"content": "<div id=\"readability-page-1\" class=\"page\"><div>\n\t\t\n\n\t<p><em>Text vyšel původně na <a href=\"https://sw-samuraj.cz/2018/12/git-fork-sync/\">webu autora</a>.</em></p>\n<h2>Proč je synchronizace potřeba?</h2>\n<p>V případě, že se jedná o jednorázovou kontribuci...",
"length": 2825,
"excerpt": "Už po několikáté jsem musel vzpomínat, jak správně synchronizovat forknutý repozitář z GitHubu. Znáte to také? Nejspíš ano. Pojďme si postup připomenout společně."
}
Plaintext, žádné HTML
Hlavní výhoda Readability je, že detekuje správně hlavní obsah a odstraní zbytečný balast. Vysledkem je však, i nadále, HTML verze dokumentu.
Readability vrací objekt Article, kde property content obsahuje HTML kód k vyrenderování. Takový text můžeme obalit třeba pomocí JSDOM.fragment(article.content) a nad výsledkem zavolat .innerHtml. Tahle naivní implementace sice vrátí HTML text, často ale poškozený – slova jsou slepená dohromady.
Proto je lepší projít celý DOM tree a jednotlivé elementy si posbírat a pospojovat sám. Hint: child.nodeType === 1 je element, který rekurzně zpracuji, child.nodeType === 3 je čistý text, ten ukládám a propaguji. Nakonec celý text pospojuji, odstraním duplicitní mezery, trim…
Pozor na to, že Readability modifikuje poskytnutý DOM – odstraňuje z něj elementy. Pokud tak potřebujete ze stránky získat i jiná data, třeba první H1 ve stránce, raději tak učiňte dřív, než předáte DOM Readability. Pak už se k některým datům nemusíte vůbec dostat.
Škálujeme
Naše Readability služba je zcela bezestavová – přijme URL z requestu, vrátí metadata a text článku nebo chybový stav. Zpracování stránky pak vyžaduje určitý čas, paměť a procesor. Taková věc ale se velmi dobře škáluje. Žádné uložiště, žádné sessions, žádné transakce. Škálovat je možné třeba pomocí pm2, nebo i ve velkém, například v kubernetes.
Problém je uhlídat timeouty a veškeré situace, kdy se zpracování zasekne, zacyklí, přestane reagovat. Ne vždy je to nutně problém Readability, může jít o načtení dat z internetu, parsování robots.txt zpracování DOMu. Na některé problémy postačí nastavit timeouty pro Request. Pokud se ale zasekne samotné zpracování a zablokuje event loop, žádný timeout nepomůže. Proto spouštíme Readability ve vlastních procesech pomocí worker-nodes s přislušně nastavenými timeouty. Taková konfigurace pohlídá jak Request a JSDOM tak Readability.
Ale tahle stránka nefunguje!
Může se stát, že narazíte na stránku, která by, dle vašeho očekávání, měla fungovat a Readability není schopno hlavní obsah detekovat. Pak by bylo vhodné doplnit server do test suite původního projektu Readability.
Nejsnadněji pomocí předpřipraveného skriptu:
npm run generate-testcase zdrojak https://www.zdrojak.cz/clanky/git-fork-synchronizace/
Kde první parametr je adresář (slug) do kterého budou testovací data uložena. Druhý parametr pak adresa konkrétního článku. Skript vygeneruje tři soubory: expected.html, expected-metadata.json a source.html.
Source obsahuje celý HTML kód odkazované stránky. Expected.html kód hlavního obsahu, tak, jak jej momentálně vidí Readability. Metadata jsou pak vyextrahovaná data článku:
{
"title": "Git fork synchronizace - Zdroják",
"byline": "Vít Kotačka",
"dir": null,
"excerpt": "Už po několikáté jsem musel vzpomínat, jak správně synchronizovat forknutý repozitář z GitHubu. Znáte to také? Nejspíš ano. Pojďme si postup připomenout společně.",
"siteName": "Zdroják",
"readerable": true
}
Takhle připravený test můžeme manuálně upravit. Ať už expected.html nebo expected-metadata.json.
Test spustíme příkazem
./node_modules/mocha/bin/mocha test/test-*.js -g zdrojak
Failující test s očekávanými daty by bylo vhodné přiložit ke každému pull requestu nebo issue, pokud sice dovedeme vytvořit test ale už ne upravit zdrojový kód Readability. Dáte tím jasně najevo, které hodnoty od Readability očekáváte.
Jak to šlape
Readability (as a Service) máme v produkci zhruba rok a půl, za tu dobu zpracovala miliony stránek. Ze začátku byl problém uhlídat všechny timeouty, nekonečné smyčky a chybové stavy. Především díky worker-nodes se ale povedlo dostat celou službu do velmi stabilního stavu a poslední měsíce nezaznamenáváme žádné výpadky ani problémy.
Kvalita detekce je velmi slušná, navíc celý projekt Readability obsahuje velkou sadu testů a neustále je vylepšován. To, že za Readability stojí Mozilla a probíhá aktivní vývoj je obrovská výhoda. Stejně tak jako shodné výsledky s reader view ve Firefoxu, které umožní i méně technicky zdatným vidět, co se s načtenou stránkou na serveru děje.